- Looker から Snowflake への OAuth 接続
- Looker (Google Cloud core) 30日間 フリートライアル設定
- AWS 落穂拾い (Security)
- AWS 落穂拾い (Storage)
- マイクロマウス
- 概要
- AWS Glue ETL 概略図
- AWS Glue が利用する IAM ロールの作成
- S3 と RDS に検証用のデータを用意
- Redshift の設定
- Crawler を設定してカタログ Table を作成
- ETL Job を作成
- PySpark 開発環境の構築
- PySpark スクリプトを編集して ETL Job を実行
- PySpark チートシート
- RDD 永続化について
- 可視化
- PySpark スクリプトを記述する際の参考資料
概要
AWS Glue を利用すると Apache Spark をサーバーレスに実行できます。基本的な使い方を把握する目的で、S3 と RDS からデータを Redshift に ETL (Extract, Transform, and Load) してみます。2017/12/22 に東京リージョンでも利用できるようになりました。また、本ページでは Python を利用しますが、新たに Scala サポートされています。
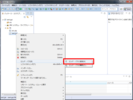
AWS Glue ETL 概略図
AWS Glue を ETL サービスとして利用する場合のシステム概略図は以下のようになります。
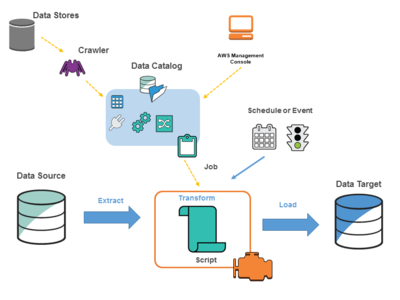
- Data Source から Data Target に対して ETL します。本ページでは Data Source は S3 と RDS であり、Data Target は Redshift となります。
- ETL は Job として実行されます。Job は cron のように定期実行したり、Lambda などからイベント駆動で実行できます。任意のタイミングで手動実行することもできます。
- ETL Job は AWS Glue 内でサーバーレスに処理されます。内部的には Apache Spark が稼動しており、特に Python で記述された PySpark のスクリプトを利用します。
- ETL Job を定義する際は Data Source を Data Catalog から選択します。Data Target は Job 定義時に新規作成するか、Data Catalog から選択します。
- Data Catalog は Crawler が収集した情報をもとに作成されたメタデータです。データのカタログであり、実際のデータではありません。
- Data Catalog は Table として管理されます。複数の Table を Database としてまとめて管理します。
AWS Glue が利用する IAM ロールの作成
IAM ロールを AWS service で Glue を選択して新規作成します。ここではロール名を my-glue-role-20171124 として作成しますが、権限の制限された IAM で作業している場合等を考慮する場合は "AWSGlueServiceRole" という文字列で始まる名称を設定します。ポリシーとしては Glue, S3, RDS, Redshift を操作するために必要なものを設定します。
- ロール名:
my-glue-role-20171124 - AWS service:
Glue - ポリシー
AWSGlueServiceRoleAmazonS3FullAccessAmazonRDSFullAccessAmazonRedshiftFullAccess
S3 と RDS に検証用のデータを用意
S3 と RDS を Glue と同じリージョンに作成して検証用のデータを格納します。今回、RDS は Glue と同じ VPC 内のパブリックサブネットに所属させますが、実際には踏み台サーバーをパブリックサブネットに用意して、RDS はプライベートサブネットに所属させた方が安全です。また、S3 はインターネットを経由しないように VPC Endpoints を作成することもできますが、今回は設定しないで進めます。必要になり次第後から設定できます。
VPC
Glue から RDS や後述の Redshift にアクセスするためには VPC に関して以下の設定が必要であることに注意します。
- RDS や Redshift は Glue と同じ VPC に存在する必要があります。
- enableDnsHostnames と enableDnsSupport が true になっている必要があります。
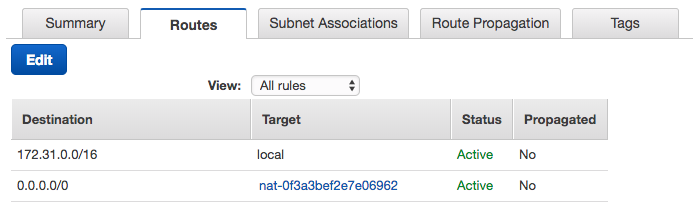
- Glue は Public IP を持ちません。そのため、VPC 内に Glue から利用するプライベートサブネットを新規に作成して、NAT Gateway をデフォルトゲートウェイとしてルーティングテーブルを設定します。NAT Gateway 自体はパブリックサブネットに所属させる必要があることに注意してください。これは Glue から RDS/Redshift にインターネット経由でアクセスすることを意味してはおらず、RDS/Redshift の Publicly Accessible 設定は No でも Yes でも問題ありません。今回は簡単のためインターネット経由で操作したいため Yes として RDS/Redshift はパブリックサブネットに所属させます。
プライベートサブネットのルーティングテーブルで、デフォルトゲートウェイを「パブリックサブネットに所属する NAT Gateway」に設定
S3
新規バケット my-bucket-20171124 を作成して、以下のような JSON ファイルをアップロードします。
s3://my-bucket-20171124/s3.json
{"pstr":"aaa","pint":1}
{"pstr":"bbb","pint":2}
{"pstr":"ccc","pint":3}
{"pstr":"ddd","pint":4}
{"pstr":"eee","pint":5}
RDS
新規 MySQL DB とユーザーを以下のように作成します。セキュリティグループは後に VPC 内の Glue からアクセスできるように「同じセキュリティグループが設定されているアクセス元であれば許可する」という設定がなされたものを追加するようにします。インターネットからアクセスできる必要はなく、Publicly Accessible は No でも Yes でも問題ありません。mydw.xxxx.us-east-1.redshift.amazonaws.com や myrdsdb.xxxx.us-east-1.rds.amazonaws.com といったホスト名は VPC 内ではプライベート IP に解決されます。
- DB 名: myrdsdb
- ユーザー名: myuser
- パスワード: mypass
myrdsdb 内に以下のようなテーブルとレコードを作成します。
GRANT ALL ON myrdsdb.* TO 'myuser'@'%' IDENTIFIED BY 'mypass';
CREATE TABLE myrdsdb.myrdstable (id INT PRIMARY KEY AUTO_INCREMENT, cstr VARCHAR(32), cint INT);
INSERT INTO myrdsdb.myrdstable (cstr, cint) VALUES ('aaa', -1), ('bbb', -2), ('ccc', -3), ('ddd', -4), ('eee', -5);
Redshift の設定
ETL 先となる Redshift を Glue と同じ VPC のパブリックサブネットに作成します。実際には踏み台サーバーをパブリックサブネットに用意して、Redshift はプライベートサブネットに所属させた方が安全です。psql コマンドの簡易チートシートについてはこちらのページもご参照ください。
psql -h mydw.xxxx.us-east-1.redshift.amazonaws.com -p 5439 mydw username
ユーザーと DB mydw 内のテーブルを作成します。
CREATE USER myuser WITH PASSWORD 'myPassword20171124';
CREATE TABLE mytable (cstr VARCHAR(32), cint INTEGER);
削除時
DROP USER myuser;
DROP TABLE mytable;
セキュリティグループは後に VPC 内の Glue からアクセスできるように「同じセキュリティグループが設定されているアクセス元であれば許可する」という設定がなされたものを追加するようにします。インターネットからアクセスできる必要はなく、Publicly Accessible は No でも Yes でも問題ありません。mydw.xxxx.us-east-1.redshift.amazonaws.com や myrdsdb.xxxx.us-east-1.rds.amazonaws.com といったホスト名は VPC 内ではプライベート IP に解決されます。
Crawler を設定してカタログ Table を作成
Glue コンソールから Crawler を設定して S3 と RDS それぞれのカタログ Table を作成します。こちらの公式ブログに記載されているとおり GUI 設定を繰り返すだけです。
Database の作成
Glue におけるメタデータ格納用 Table をまとめるための Database を作成します。
- Database name: mygluedb
Connections の作成
JDBC 接続で利用する認証情報を登録します。Connection type で RDS や Redshift を指定すると JDBC 設定が多少簡略化されますが、ここでは Connection type JDBC として設定します。設定後は「Test connection」ボタンで正常に接続できるか試験できます。
RDS
- Connection name: my-rds-connection
- Connection type: JDBC
- JDBC URL: VPC 内の Glue がアクセスするためのエンドポイントを設定します。JDBC URL のサンプルはこちらです。
jdbc:mysql://myrdsdb.xxxx.us-east-1.rds.amazonaws.com:3306/myrdsdbのようになります。 - Username: myuser
- Password: mypass
- VPC: Glue が所属する VPC の設定です。RDS と同じ VPC を指定します。
- Subnet: Glue が所属する Subnet の設定です。RDS が存在する Subnet と通信できるものを指定します。前述のとおり Glue は Public IP を持たないため、NAT Gateway にルーティングされるプライベート Subnet を選択します。
- Security groups: Glue に設定する Security groups です。RDS にも設定した「同じセキュリティグループが設定されているアクセス元であれば許可する」という設定がなされたものを追加します。この RDS と同一のセキュリティグループを設定することで、RDS へのアクセスが許可されるようになります。
Redshift
- Connection name: my-redshift-connection
- Connection type: JDBC
- JDBC URL: VPC 内の Glue がアクセスするためのエンドポイントを設定します。JDBC URL のサンプルはこちらです。
jdbc:redshift://mydw.xxxx.us-east-1.redshift.amazonaws.com:5439/mydwのようになります。 - Username: myuser
- Password: myPassword20171124
- VPC: Glue が所属する VPC の設定です。Redshift と同じ VPC を指定します。
- Subnet: Glue が所属する Subnet の設定です。Redshift が存在する Subnet と通信できるものを指定します。前述のとおり Glue は Public IP を持たないため、NAT Gateway にルーティングされるプライベート Subnet を選択します。
- Security groups: Glue に設定する Security groups です。Redshift にも設定した「同じセキュリティグループが設定されているアクセス元であれば許可する」という設定がなされたものを追加します。この Redshift と同一のセキュリティグループを設定することで、Redshift へのアクセスが許可されるようになります。
Crawlers の作成
S3 のデータをカタログ化する Crawler を登録します。
- Crawler name: my-s3-crawler-20171124
- Data store: S3
- Crawl data in: Specified path in my account
- Include path: s3://my-bucket-20171124/s3.json
- Choose an existing IAM role: my-glue-role-20171124
- Frequency: Run on demand
- Database: mygluedb
- Prefix added to tables:
mys3prefix_
RDS のデータをカタログ化する Crawler を登録します。
- Crawler name: my-rds-crawler-20171124
- Data store: JDBC
- Connection: my-rds-connection
- Include path: myrdsdb/myrdstable
- Choose an existing IAM role: my-glue-role-20171124
- Frequency: Run on demand
- Database: mygluedb
- Prefix added to tables:
myrdsprefix_
それぞれ手動実行して CloudWatch にログが出力されることを確認します。今回のように Data store 毎に Crawlers を分けることは必須ではなく、似たような Data store であれば同じ Crawler にまとめて登録します。結果として一つの Crawler から複数の Table が生成されます。Crawler は Table に対して大量に作成するようなものではありません。
ETL Job を作成
Glue コンソールから Job を登録します。具体的には ETL のソースとターゲットを設定します。設定内容をもとに PySpark スクリプトが自動生成されます。
- Name: myjob-20171124
- IAM role: my-glue-role-20171124
- This job runs: A proposed script generated by AWS Glue (スクリプトを自動生成する設定にします。ここで自分のスクリプトを最初から設定することもできます)
- Script file name: myjob-20171124
- S3 path where the script is stored: s3://aws-glue-scripts-xxxx-us-west-2/admin (スクリプトは S3 上に生成されます)
- Temporary directory: s3://aws-glue-scripts-xxxx-us-west-2/tmp (Job 実行のためには一時ファイルなどが必要になるため S3 のフォルダを指定する必要があります)
- Choose your data sources:
mys3prefix_s3_json(ここでは S3 を指定していますが、後でスクリプトを編集することで RDS も Source として扱えます) - Choose your data targets: Create tables in your data target (ETL 出力先は Redshift を指定します)
- Data store: JDBC
- Connection: my-redshift-connection
- Database name: mydw
- Map the source columns to target columns: PySpark スクリプト自動生成のヒントとなります。使用しない Source 情報は Target から除外します。
- Job 作成後、Edit job で
my-rds-connectionを Required connections に追加します。
PySpark 開発環境の構築
生成された PySpark スクリプトは Job の「Edit script」ボタンからエディタを開いて確認できます。このまま編集して保存することもできますが、動作検証の度に Run job するのは時間がかかります。以下の開発環境を構築して十分に検証してから Run job すると効率的です。
エンドポイントの作成
Apache Spark への踏み台となる EC2 インスタンスを、開発環境から利用するエンドポイントとして作成します。Glue コンソールの Dev endpoints から GUI で作成できます。READY 状態のエンドポイントは課金対象となります。安くはないため、費用を抑えるためには例えば DPU を 2 として作成します。DPU 1 だと作成に失敗します。
- Development endpoint name: myendpoint-20171124
- IAM role: my-glue-role-20171124 (本ページ上部で作成した Glue から利用する IAM ロール)
- Data processing units (DPUs): 2
- Networking: インターネット経由で S3 のみ利用する場合は Skip networking information で問題ありません。RDS や Redshift を利用する場合は Choose a connection から作成済みのものを選択して VPC にこれから作成する EC2 インスタンスを所属させる必要があります。
- Public key contents: これからエンドポイントとして作成する、Apache Spark への踏み台となる EC2 インスタンスに SSH するための公開鍵を登録します。普段使用しているものを登録するか、ここで新規に作成します。
作成されるまでしばらくかかります。
PySpark 開発環境の選択
エンドポイントとして作成した Apache Spark への踏み台となる EC2 インスタンスを利用する開発環境としては、以下の三つの構築方法があります。
- 登録した公開鍵に対応する秘密鍵でエンドポイントに SSH して REPL シェルを利用
- 登録した公開鍵に対応する秘密鍵でエンドポイントに SSH して
-Lオプションでポート転送した状態で、Apache Zeppelin を ローカル PC で起動してエンドポイントに接続 - Glue サービスが提供する CloudFormation で Apache Zeppelin が動作する EC2 インスタンスを構築
三番目の選択肢が便利ですが、費用がかかります。二番目の選択肢は若干手間がかかりますが、費用が抑えられます。一番目の選択肢は簡単な検証時に有用です。SSH コマンドは作成したエンドポイントの詳細画面からコピーして利用できます。また、二番目の選択肢において Docker を利用する場合は、ホスト側のサービスをコンテナ内から利用することになるため ssh ポート転送時に -g オプションを付与する必要があることや、Zeppelin 設定時に localhost ではなくホストの IP を指定する必要があることに注意します。
IAM ロールの作成
三番目の選択肢で Apache Zeppelin が稼動する EC2 インスタンスを CloudFormation で起動する場合は、事前に EC2 インスタンスで利用する IAM ロールを作成する必要があります。S3, RDS, Redshift すべてを利用する場合は以下のようになります。
- ロール名:
my-ec2-glue-notebook-role-20171124 - AWS service:
EC2 - ポリシー
AWSGlueServiceNotebookRoleAmazonS3FullAccessAmazonRDSFullAccessAmazonRedshiftFullAccess
PySpark スクリプトを編集して ETL Job を実行
構築した開発環境で PySpark スクリプトを編集します。検証まで完了したら ETL Job として実行します。以下に編集例を記載します。Zeppelin 操作時は %pyspark で記述し始める必要があることに注意します。
Data Source から情報を取得して表示する例
%pyspark
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import udf
from pyspark.sql.functions import desc
# AWS Glue を操作するオブジェクト
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
# S3 からデータを取得
srcS3 = glueContext.create_dynamic_frame.from_catalog(
database = 'mygluedb',
table_name = 'mys3prefix_s3_json')
# 情報を表示
print 'Count:', srcS3.count()
srcS3.printSchema()
# S3 から取得したデータを、加工せずにそのまま S3 に CSV フォーマットで出力
glueContext.write_dynamic_frame.from_options(
frame = srcS3,
connection_type = 's3',
connection_options = {
'path': 's3://my-bucket-20171124/target'
},
format = 'csv')
S3 出力例
$ aws s3 ls s3://my-bucket-20171124/target/
2017-11-26 15:59:44 40 run-1511679582568-part-r-00000
$ aws s3 cp s3://my-bucket-20171124/target/run-1511679582568-part-r-00000 -
pstr,pint
aaa,1
bbb,2
ccc,3
ddd,4
eee,5
標準出力例
Count: 5
root
|-- pstr: string
|-- pint: int
ETL Job として実行する際は %pyspark を削除して、以下のように Job の初期化と終了の処理を追記します。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import udf
from pyspark.sql.functions import desc
# AWS Glue を操作するオブジェクト
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
# Job の初期化 ←追加
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# S3 からデータを取得
srcS3 = glueContext.create_dynamic_frame.from_catalog(
database = 'mygluedb',
table_name = 'mys3prefix_s3_json')
# 情報を表示
print 'Count:', srcS3.count()
srcS3.printSchema()
# S3 から取得したデータを、加工せずにそのまま S3 に CSV フォーマットで出力
glueContext.write_dynamic_frame.from_options(
frame = srcS3,
connection_type = 's3',
connection_options = {
'path': 's3://my-bucket-20171124/target'
},
format = 'csv')
# Job を終了 ←追加
job.commit()
S3 出力例
$ aws s3 ls s3://my-bucket-20171124/target/
2017-11-26 15:59:44 40 run-1511679582568-part-r-00000
$ aws s3 cp s3://my-bucket-20171124/target/run-1511679582568-part-r-00000 -
pstr,pint
aaa,1
bbb,2
ccc,3
ddd,4
eee,5
CloudWatch 出力一部例
LogType:stdout
Log Upload Time:Sun Nov 26 06:59:44 +0000 2017
LogLength:46
Log Contents:
Count: 5
root
|-- pstr: string
|-- pint: int
End of LogType:stdout
PySpark チートシート
AWS Glue DynamicFrame と Apache Spark DataFrame は toDF() および fromDF() で互いに変換できます。AWS Glue が提供する DynamicFrame では表現できない処理が存在する場合、「データソースから取得したデータのキャストや不要なフィールドの除去」および「最終的な構造の変換とデータ出力」の間に発生する「データ変換」は Apache Spark の DataFrame に変換して記述します。DataFrame 関連のドキュメントを調査する際には Python の dir と help 関数の存在も知っておきます。
DynamicFrame / 入力データの整形
filter
srcS3.filter(lambda r: r['pint'] > 1).toDF().show()
+----+----+
|pint|pstr|
+----+----+
| 2| bbb|
| 3| ccc|
| 4| ddd|
| 5| eee|
+----+----+
フィールドを選択
srcS3.select_fields(['pstr']).toDF().show()
+----+
|pstr|
+----+
| aaa|
| bbb|
| ccc|
| ddd|
| eee|
+----+
フィールドを除外
srcS3.drop_fields(['pstr']).toDF().show()
+----+
|pint|
+----+
| 1|
| 2|
| 3|
| 4|
| 5|
+----+
フィールドの名称を変更
srcS3.rename_field('pstr', 'pstr2').toDF().show()
+----+-----+
|pint|pstr2|
+----+-----+
| 1| aaa|
| 2| bbb|
| 3| ccc|
| 4| ddd|
| 5| eee|
+----+-----+
型変換
キャスト可能な型はこちらです。
srcS3.resolveChoice(specs = [('pstr', 'cast:int')]).toDF().show()
+----+----+
|pstr|pint|
+----+----+
|null| 1|
|null| 2|
|null| 3|
|null| 4|
|null| 5|
+----+----+
DynamicFrame / データの変換