概要
こちらのページでインストールした PyTorch の基本的な使い方を記載します。
テンソルの計算
初期化されていない空のテンソルを作成
import torch
x = torch.empty(5, 3)
乱数で初期化 (一様分布、標準正規分布)
x = torch.rand(5, 3)
x = torch.randn(4, 4)
0 で初期化
x = torch.zeros(5, 3, dtype=torch.long)
1 で初期化
x = torch.ones(5)
値を指定して初期化
x = torch.tensor([5.5, 3])
同じ形状のテンソルを作成
x = torch.randn_like(x, dtype=torch.float)
サイズを取得
x.shape
形状を変更
y = x.reshape(16)
テンソルの値を取り出す
x = torch.randn(1)
a = x.item()
NumPy に変換
b = a.numpy()
NumPy から変換
import numpy as np
a = np.ones(5)
b = torch.from_numpy(a)
自動微分
こちらのページでも記載したバックプロパゲーションによる微分が利用できます。
$$y = x^2 \\ \frac{dy}{dx} = 2 x \\ \frac{dy}{dx}|_{x=1.0} = 2.0 $$
これを PyTorch で表現すると以下のようになります。
x = torch.tensor(1.0, requires_grad=True)
y = x * x
y.backward()
print(x.grad) #=> tensor(2.)
PyTorch で実装されている関数には backward 処理が実装されているため、例えば以下のような ReLU (rectified liner unit) を考えたときにも対応できます。
$$h(x) = \begin{cases} x & (x \geq 0) \\ 0 & (otherwize) \end{cases} $$
torch.clamp を利用します。
x = torch.tensor(1e-6, requires_grad=True)
y = x.clamp(min=0)
y.backward()
print(x.grad) #=> tensor(1.)
x = torch.tensor(-1e-6, requires_grad=True)
y = x.clamp(min=0)
y.backward()
print(x.grad) #=> tensor(0.)
非線形なデータセットを用いた 2 層のニューラルネットワークの学習
一般的なニューラルネットワークは
「線形変換」→「活性化関数 → 線形変換」→ ... →「活性化関数 → 線形変換」
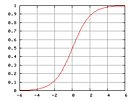
という構造になっています。活性化関数には上述の ReLU や、以下のシグモイド関数があります。活性化関数では非線形な変換が行われるため、ニューラルネットワークでは非線形なデータセットにも対応できます。
$$y = \frac{1}{1 + \exp(-x)} $$
活性化関数にはパラメータがありませんが、線形変換には重み w とバイアス b パラメータがあります。以下の例のように、パラメータを持つ層が二つ存在する場合は 2 層のニューラルネットワークとよびます。入力データ $x_i$ と出力データ $y_i$ をもとに、ニューラルネットワークのパラメータ w1、w2、b1、b2 を学習します。損失関数 (Loss Function) として用いている平均二乗誤差 Mean Squared Error (MSE) が小さくなるように、勾配降下法によって最適化を行います。
$$L = \frac{1}{N} \sum_{i=0}^N (f(x_i) - y_i)^2 $$
# -*- coding: utf-8 -*-
import torch
from math import pi
import matplotlib.pyplot as plt
def Main():
dtype = torch.float # 計算時に利用する型
device = torch.device('cpu') # GPU ではなく CPU を利用する例
N = 128 # データ数
DIn = 1 # 入力層の次元数
H = 10 # 隠れ層の次元数
DOut = 1 # 出力層の次元数
# 入力データを乱数で用意 (実際には学習用のデータを用意します)
x = torch.rand(N, DIn, device=device, dtype=dtype)
# 出力データを乱数で用意 (実際には学習用のデータを用意します)
y = torch.sin(2 * pi * x) + torch.rand(N, DOut, device=device, dtype=dtype)
# 学習すべきパラメータである、重みとバイアスです。
w1 = torch.randn(DIn, H, device=device, dtype=dtype, requires_grad=True)
b1 = torch.zeros(1, device=device, dtype=dtype, requires_grad=True)
w2 = torch.randn(H, DOut, device=device, dtype=dtype, requires_grad=True)
b2 = torch.zeros(1, device=device, dtype=dtype, requires_grad=True)
# 学習率、学習の反復回数
learningRate = 0.2
iters = 20000
for t in range(iters):
yPred = x.mm(w1) + b1 # 線形変換
yPred = 1 / (1 + torch.exp(-yPred)) # 活性化関数 (シグモイド関数)
yPred = yPred.mm(w2) + b2 # 線形変換
# 損失関数 (平均二乗誤差)
loss = (yPred - y).pow(2).sum() / N
# デバッグ目的の出力
if t % 1000 == 999:
print(t, loss.item())
# バックプロパゲーション
loss.backward()
# パラメータ更新時には計算グラフを作る必要はありません。
with torch.no_grad():
# 勾配降下法のよる学習
w1 -= learningRate * w1.grad
w2 -= learningRate * w2.grad
b1 -= learningRate * b1.grad
b2 -= learningRate * b2.grad
# 不要になった微分計算結果を忘れる
w1.grad.zero_()
w2.grad.zero_()
b1.grad.zero_()
b2.grad.zero_()
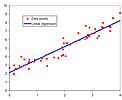
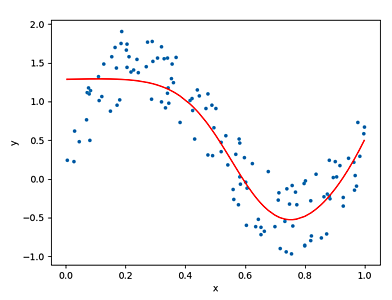
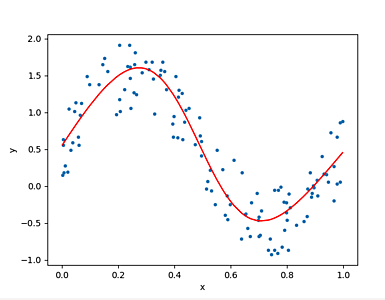
# 学習結果を表現する yPred をプロットしてみます。
xx = x.T[0]
yy = y.T[0]
yyPred = yPred.T[0]
# 描画のための処理です。ソートします。
data = list(zip(xx, yy, yyPred))
data.sort(key=lambda x: x[0])
data = torch.tensor(data)
plt.scatter(data[:,0], data[:,1], marker='.')
plt.plot(data[:,0], data[:,2], color='red')
plt.xlabel('x', fontsize=10)
plt.ylabel('y', fontsize=10)
plt.show()
if __name__ == '__main__':
Main()
実行例
999 0.283403217792511
1999 0.2734842300415039
2999 0.2467156946659088
3999 0.2012743204832077
4999 0.1550908386707306
5999 0.135251984000206
6999 0.12999556958675385
7999 0.1284925937652588
8999 0.12771515548229218
9999 0.12705880403518677
10999 0.1264435052871704
11999 0.12586960196495056
12999 0.1253361850976944
13999 0.12483663856983185
14999 0.1243625283241272
15999 0.12390581518411636
16999 0.12346050888299942
17999 0.1230253353714943
18999 0.12260625511407852
19999 0.12221628427505493
データのプロットでは Matplotlib を利用しています。
PyTorch の関数は自分で追加することができます。こちらのページと同様に forward と backward を実装します。シグモイド関数の例は以下のようになります。
class MySigmoid(torch.autograd.Function):
@staticmethod
def forward(ctx, x0):
ctx.save_for_backward(x0)
return 1 / (1 + torch.exp(-x0))
@staticmethod
def backward(ctx, gy):
x0, = ctx.saved_tensors
gy = gy.clone()
y0 = 1 / (1 + torch.exp(-x0))
return (1 - y0) * y0 * gy
これを用いると上記サンプルプログラムは以下のように変更できます。バックプロパゲーションの計算グラフが簡単になるためメモリ効率が良くなります。
for t in range(iters):
+ sigmoid = MySigmoid.apply
yPred = x.mm(w1) + b1 # 線形変換
- yPred = 1 / (1 + torch.exp(-yPred)) # 活性化関数 (シグモイド関数)
+ yPred = sigmoid(yPred) # 活性化関数 (シグモイド関数)
yPred = yPred.mm(w2) + b2 # 線形変換
既存の nn モジュールを組み合わせてモデルを構築
torch.nn ではよく利用するモジュールが提供されています。モジュールを組み合わせてモデルを作ることで、先程の例における、線形変換およびシグモイド関数による 2 層のニューラルネットワークを構築できます。損失関数も提供されているものを利用できます。
# -*- coding: utf-8 -*-
import torch
from math import pi
import matplotlib.pyplot as plt
def Main():
dtype = torch.float # 計算時に利用する型
device = torch.device('cpu') # GPU ではなく CPU を利用する例
N = 128 # データ数
DIn = 1 # 入力層の次元数
H = 10 # 隠れ層の次元数
DOut = 1 # 出力層の次元数
# 入力データを乱数で用意 (実際には学習用のデータを用意します)
x = torch.rand(N, DIn, device=device, dtype=dtype)
# 出力データを乱数で用意 (実際には学習用のデータを用意します)
y = torch.sin(2 * pi * x) + torch.rand(N, DOut, device=device, dtype=dtype)
# 標準のモジュールを組み合わせることでモデルを構築
model = torch.nn.Sequential(
torch.nn.Linear(DIn, H),
torch.nn.Sigmoid(),
torch.nn.Linear(H, DOut),
)
# 損失関数 (平均二乗誤差)
lossFn = torch.nn.MSELoss()
# 学習率、学習の反復回数
learningRate = 0.2
iters = 20000
for t in range(iters):
yPred = model(x)
loss = lossFn(yPred, y)
# デバッグ目的の出力
if t % 1000 == 999:
print(t, loss.item())
# バックプロパゲーションを行う前に微分値を消去
model.zero_grad()
# バックプロパゲーションの実行
loss.backward()
# パラメータ更新時には計算グラフを作る必要はありません。
with torch.no_grad():
for param in model.parameters():
param -= learningRate * param.grad
# 学習結果を表現する yPred をプロットしてみます。
xx = x.T[0]
yy = y.T[0]
yyPred = yPred.T[0]
# 描画のための処理です。ソートします。
data = list(zip(xx, yy, yyPred))
data.sort(key=lambda x: x[0])
data = torch.tensor(data)
plt.scatter(data[:,0], data[:,1], marker='.')
plt.plot(data[:,0], data[:,2], color='red')
plt.xlabel('x', fontsize=10)
plt.ylabel('y', fontsize=10)
plt.show()
if __name__ == '__main__':
Main()
結果はモデルを利用しない場合と同様です。
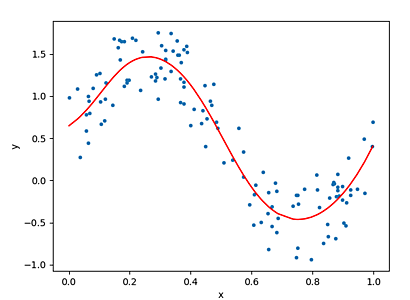
以下のように独自のモデルを定義して使うこともできます。
from math import pi
import matplotlib.pyplot as plt
+class TwoLayerNet(torch.nn.Module):
+
+ def __init__(self, DIn, H, DOut):
+ super(TwoLayerNet, self).__init__()
+ self.linear1 = torch.nn.Linear(DIn, H)
+ self.sigmoid = torch.nn.Sigmoid()
+ self.linear2 = torch.nn.Linear(H, DOut)
+
+ def forward(self, x):
+ yPred = self.linear1(x)
+ yPred = self.sigmoid(yPred)
+ yPred = self.linear2(yPred)
+ return yPred
+
def Main():
dtype = torch.float # 計算時に利用する型
@@ -20,11 +34,7 @@ def Main():
y = torch.sin(2 * pi * x) + torch.rand(N, DOut, device=device, dtype=dtype)
# 標準のモジュールを組み合わせることでモデルを構築
- model = torch.nn.Sequential(
- torch.nn.Linear(DIn, H),
- torch.nn.Sigmoid(),
- torch.nn.Linear(H, DOut),
- )
+ model = TwoLayerNet(DIn, H, DOut)
# 損失関数 (平均二乗誤差)
lossFn = torch.nn.MSELoss()
torch.optim の利用
ニューラルネットワークのパラメータを学習する際には最適化問題を解きます。ここまでの例では、簡単な勾配降下法を実装して利用していましたが、torch.optim で提供されているものを利用することもできます。勾配降下法の一つである SGD (stochastic gradient descent) や、Adam を利用するためには以下のようにします。
# -*- coding: utf-8 -*-
import torch
from math import pi
import matplotlib.pyplot as plt
def Main():
dtype = torch.float # 計算時に利用する型
device = torch.device('cpu') # GPU ではなく CPU を利用する例
N = 128 # データ数
DIn = 1 # 入力層の次元数
H = 10 # 隠れ層の次元数
DOut = 1 # 出力層の次元数
# 入力データを乱数で用意 (実際には学習用のデータを用意します)
x = torch.rand(N, DIn, device=device, dtype=dtype)
# 出力データを乱数で用意 (実際には学習用のデータを用意します)
y = torch.sin(2 * pi * x) + torch.rand(N, DOut, device=device, dtype=dtype)
# 標準のモジュールを組み合わせることでモデルを構築
model = torch.nn.Sequential(
torch.nn.Linear(DIn, H),
torch.nn.Sigmoid(),
torch.nn.Linear(H, DOut),
)
# 損失関数 (平均二乗誤差)
lossFn = torch.nn.MSELoss()
# 学習率、学習の反復回数
learningRate = 0.2
# iters = 20000
# optimizer = torch.optim.SGD(model.parameters(), lr=learningRate)
iters = 2000
optimizer = torch.optim.Adam(model.parameters(), lr=learningRate)
for t in range(iters):
yPred = model(x)
loss = lossFn(yPred, y)
# デバッグ目的の出力
if t % 1000 == 999:
print(t, loss.item())
# バックプロパゲーションを行う前に微分値を消去
optimizer.zero_grad()
# バックプロパゲーションの実行
loss.backward()
# 最適化のための反復処理
optimizer.step()
# 学習結果を表現する yPred をプロットしてみます。
xx = x.T[0]
yy = y.T[0]
yyPred = yPred.T[0]
# 描画のための処理です。ソートします。
data = list(zip(xx, yy, yyPred))
data.sort(key=lambda x: x[0])
data = torch.tensor(data)
plt.scatter(data[:,0], data[:,1], marker='.')
plt.plot(data[:,0], data[:,2], color='red')
plt.xlabel('x', fontsize=10)
plt.ylabel('y', fontsize=10)
plt.show()
if __name__ == '__main__':
Main()
実行例
999 0.07238689810037613
1999 0.07160747051239014
学習済みモデルのファイル保存
学習したパラメータはファイルシステムに保存することができます。
torch.save(model.state_dict(), './state_dict_model.pt')
読み込んで利用
model.load_state_dict(torch.load('./state_dict_model.pt'))
model.eval()