概要
G検定のシラバスにおける「機械学習の具体的手法」に関連する事項を記載します。
線形回帰
説明変数、目的変数
説明変数と目的変数が、直線や超平面といった、線形の関係にある状態を線形回帰とよびます。説明変数が 2つ以上の場合を重回帰とよびます。線形回帰を用いたモデルの学習は、教師あり学習です。
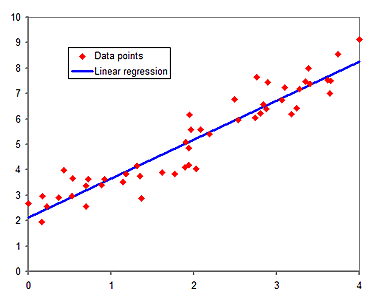
偏回帰係数
回帰係数 $\beta$ は、説明変数 $x$ がどの程度 $y$ を説明するために寄与しているかを表します。
$$y = \alpha + \beta x $$
重回帰の場合の回帰係数を特に偏回帰係数とよびます。
帰無仮説
観測された標本を用いてその母集団の性質を判断する手続きを、統計的仮説検定とよびます。
統計的仮説検定において立てる仮説を帰無仮説とよび、これが否定されることによって、対立仮説が真であることを証明できます。
説明変数の重要さについて
正規化によって、各説明変数のスケールを揃えます。このとき、
- 回帰係数が 0 である場合、対応する説明変数は重要でないと言えます。
- 回帰係数の絶対値が大きい場合、対応する説明変数は重要であると言えます。
多重共線性
重回帰において、説明変数どうしの相関が高すぎる場合、回帰係数を求めたりすることが困難になります。
この問題を多重共線性とよびます。
該当する説明変数をその他の説明変数で回帰するモデルを推定し、相関係数が非常に高くならないことを確認したりして回避します。
説明変数の主成分を新たな説明変数として用いることや、Ridge 回帰を適用することでも回避できます。
リンク関数
単純な線形回帰モデルでは、目的変数が $(-\infty, \infty)$ の値をとります。
一般化線形モデルでは、説明変数の線形結合をリンク関数とよばれる関数で変換することで、目的変数の取り得る値の範囲を変更します。
$$y = f(\beta_1 x_1 + \beta_2 x_2 + \dots) $$
特に、リンク関数によって取り得る値を 0 または 1 に変換した場合をロジスティック回帰とよびます。二値分類問題で利用されます。
ロジスティック回帰
上述のリンク関数として、シグモイド関数を考えます。
$$y = \frac{1}{1 + \exp(-(\beta_1 x_1 + \beta_2 x_2 + \dots))} = \frac{1}{1 + \exp(-l)} $$
目的変数 $y$ の値の取り得る範囲は $(0, 1)$ です。確率 $p$ として捉えることができます。
オッズ
$$\frac{p}{1 - p} = \exp(l) $$
対数オッズ
オッズの対数をとると、線形回帰が適用できることが分かります。教師あり学習として、対数オッズの偏回帰係数を学習できます。
$$l = \log\left(\frac{p}{1 - p}\right) = \beta_1 x_1 + \beta_2 x_2 + \dots $$
閾値による二値分類
対数オッズ $l$ が $(-\infty, \infty)$ の値をとるとき、目的変数 $y$ は $(0, 1)$ の範囲をとります。
目的変数 $y$ の値が 0.5 より大きいか小さいかによって、正例 (+1) または負例 (-1) に分類します。閾値は分類したい場合によって 0.5 より小さくしたり大きくしたりします。
二値分類ではなく多値分類を行いたい場合は、シグモイド関数の代わりにソフトマックス関数を用います。
正則化
正規化 (せいきか)
正則化と正規化を区別します。正規化は、例えば $[0, 1]$ の範囲に値を揃えることを指します。
正則化 (せいそくか)
機械学習において、過学習を防ぐための手法の一つです。目的関数に対して、正則化項を足します。
新たな目的関数 L' = 目的関数 L + 正則化項
目的関数の例として、ニューラルネットワークの学習における損失関数の一つである、平均二乗誤差があります。
Lasso 回帰、Ridge 回帰
正則化項は、正則化パラメータ $\lambda$ と、線形回帰における各説明変数の回帰係数 $w_i $ を用いて構成します。$\lambda$ はハイパーパラメータであり、事前に定数として設定します。
ある特定の $i$ に対して、$w_i $ が大きくなり過ぎないように制御され、過学習が回避されることが期待できます。
$$L' = L + \lambda \sum_i |w_i|^p $$
- $p = 1$ の場合を L1 正則化、あるいは Lasso 回帰とよびます。
- 回帰係数が、ちょうど 0 となるものが多くなります。説明変数を選択することに相当します。
- $p = 2$ の場合を L2 正則化、あるいは Ridge 回帰とよびます。
- 回帰係数が 0 に近づくようになります。
Lasso 回帰
$$L' = L + \lambda \sum_i |w_i| $$
Ridge 回帰
$$L' = L + \lambda \sum_i w_i^2 $$
Lasso 回帰と Ridge 回帰を組み合わせた手法を Elastic Net とよびます。
サポートベクターマシン (SVM)
- 教師あり学習です。
- 分類問題
- 回帰問題 (サポートベクトル回帰 SVR)
- サンプルコード
k近傍法
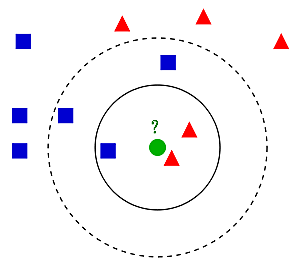
- 教師あり学習の手法の一つです。
- 特徴空間において、未知のデータを分類するために、最も近い $k$ 個の学習データをもとにします。
- スケールが大きい特徴量に左右されすぎないように、適切な前処理を行ない、特徴量のスケールを揃える必要があります。
- $k$ を大きくするとモデルは単純もしくは滑らかになり、$k$ を小さくするとモデルは複雑で入り組んだものになります。
- $k = 1$ の場合を最近傍法とよびます。
決定木、ランダムフォレスト
決定木
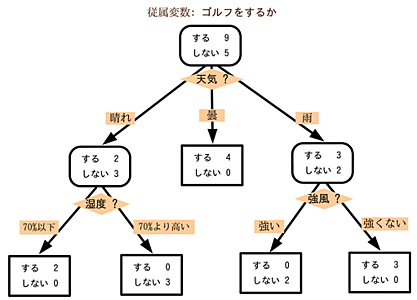
- 教師あり学習の手法の一つです。分類問題および回帰問題。
- 木を成長させていくと、1つの葉に対応するデータが1つだけになり、過学習された状態となります。
- 木の深さおよび幅が大きくなり過ぎないように注意します。
- 木の深さは、根を 0 としてカウントします。
ランダムフォレスト
- 教師あり学習の手法の一つです。分類問題および回帰問題。
- 複数の決定木を用いてアンサンブル学習します。
- 木の数を多くしても過学習にはなりません。
- 並列にそれぞれの決定木を学習できます。
- ある決定木の学習時には、学習用のデータから、重複ありでランダムにサンプリングしたデータセットを用います (bootstrap sampling)。
- 更にそれぞれの決定木を統合するところまで含めて「バギング」とよびます。
- ある決定木で用いる特徴量 (説明変数) の選択も、ランダムサンプリングします。
特徴量の重要度
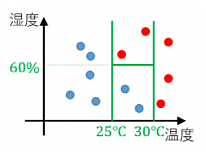
https://mathwords.net/ketteigi
決定木における、それぞれの特徴量での分割回数が多いほど、その特徴量は重要であると考えられます。
アンサンブル学習の用語の整理
勾配ブースティング
教師あり学習です。「多数の弱いモデルで強いモデルを作るアンサンブル学習」であるブースティングの一つです。
用語の整理
- アンサンブル学習
- バギング (bagging; bootstrap aggregation)
- → ランダムフォレストで用いられる手法です。
- → 複数の決定木を並列に学習可能です。
- → 決定木の数を増やしても過学習になりません。
- ブースティング
- → 弱い学習器を逐次的に学習する手法です。
- → 学習器としては、決定木に限らず、線形回帰も利用されます。
- → 弱学習器の数が多くなりすぎると過学習が起きます。
- 勾配ブースティング
- 勾配ブースティング木 (GBDT; Gradient Boosting Decision Tree)
- → 弱学習器に決定木を用いる場合です。
- catboost → ライブラリの名称
- lightgbm → ライブラリの名称
- xgboost → ライブラリの名称
- 勾配ブースティング木 (GBDT; Gradient Boosting Decision Tree)
- adaboost
- スタッキング
- → あるモデルによる予測値を、新たなモデルの特徴量とします。
- バギング (bagging; bootstrap aggregation)
k-means 法
- 教師なし学習の手法の一つです。
- 非階層的なクラスタリングを行います。
- 「クラスタリング」は一般に教師なし学習となります。
- クラスタの数 $k$ は予め指定しておく必要があります。
- 複数のクラスタに所属するデータのない、ハードなクラスタリングです。
- 観測データが各クラスタに所属する割合や確率を出力する場合を、ソフトクラスタリングとよびます。
階層的クラスタリング (ウォード法)
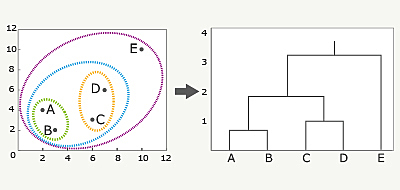
https://www.albert2005.co.jp/knowledge/data_mining/cluster/hierarchical_clustering
- 教師なし学習の手法の一つです。
- デンドログラムとよばれる樹形図で表現される、階層的クラスタリングを行います。
交差検証
- 交差検証
- → 全データを「訓練データ」と「テストデータ」に分割して検証することです。
- → 以下のいずれの手法においても、過学習は起こり得ます。
- ホールドアウト検証
- → 事前に「訓練データ」と「テストデータ」に分割します。
- k-分割交差検証
- → 「訓練データ」と「テストデータ」への分割を複数回行います。
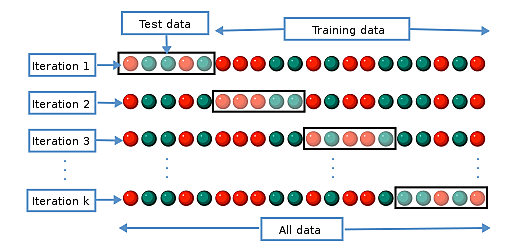
k-fold cross-validation - Wikipedia
回帰における評価指標
MSE (Mean Square Error) 平均二乗誤差
$$MSE = \frac{1}{N} \sum_{i=1}^N (y_i - \hat{y_i})^2 $$
RMSE (Root Mean Square Error)
- ルートの中で二乗して和を取っているため、MAE と比較して、外れ値 (大きな値の違い) をより大きな誤差として扱う傾向があります。
- 大きな外れ値に、大きなペナルティを与えていると言えます。
$$RMSE = \sqrt{\frac{1}{N} \sum_{i=1}^N (y_i - \hat{y_i})^2} $$
MAE (Mean Absolute Error) 平均絶対誤差
RMSE と比較して、外れ値 (大きな値の違い) にあまり影響されたくない場合に用います。
$$MAE = \frac{1}{N} \sum_{i=1}^N |y_i - \hat{y_i}| $$
RMSLE (Root Mean Squared Logarithmic Error)
目的変数と予測値の比に着目する評価指標です。
$$\begin{eqnarray} RMSLE &=& \sqrt{\frac{1}{N} \sum_{i=1}^N (log(y_i) - log(\hat{y_i}))^2} \\ &=& \sqrt{\frac{1}{N} \sum_{i=1}^N \left(\frac{log(y_i)}{log(\hat{y_i})}\right)^2} \\ \end{eqnarray} $$
分類における評価指標
混同行列
| 本当のクラス (正) | 本当のクラス (負) | |
|---|---|---|
| 予測クラス (正) | 真陽性 TP | 偽陽性 FP |
| 予測クラス (負) | 偽陰性 FN | 真陰性 TN |
正確率 (accuracy)
全体のデータのうち、正しく予測できたものの割合です。
(TP + TN) / (TP + FP + FN + TN)
適合率 (precision)
真と予測したデータのうち、実際に真であるものの割合です。再現率とトレードオフの関係にあります。
TP / (TP + FP)
再現率 (recall)
実際に真であるデータのうち、真と予測したものの割合です。適合率とトレードオフの関係にあります。
TP / (TP + FN)
F 値 (F measure)
トレードオフの関係にある「適合率」と「再現率」の調和平均です。
$$F値 = \frac{2}{\frac{1}{適合率} + \frac{1}{再現率}} $$
ROC 曲線と AUC
正確率、適合率、再現率、F値 とは異なった観点でモデルの性能を評価する手法として、ROC 曲線と AUC があります。
ROC (Receiver operating characteristic)
ロジスティック回帰において、モデルの出力自体は確率で表現されており、0.5 といった閾値を用いて正例 (+1) または負例 (-1) に分類します。
この閾値を 0.0 から 1.0 の範囲で変化させた際の予測結果の変化を曲線として表現したものが ROC 曲線です。
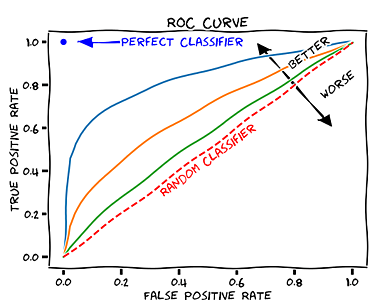
Receiver operating characteristic - Wikipedia
横軸
FPR (False Positive Rate) = FP / (FP + TN)
縦軸 (再現率と同じ定義です)
TPR (True Positive Rate) = TP / (TP + FN)
- 例えば、閾値が 0.0 の場合はすべての出力が正例に分類されます。そのため FPR と TPR はそれぞれ常に 1.0 となります。
- 閾値が 1.0 の場合はすべての出力が負例に分類されます。そのため FPR + TPR は常に 0.0 となります。
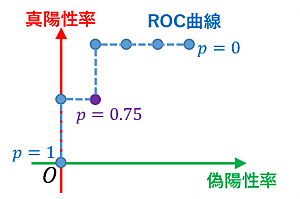
閾値を 1.0 から 0.0 に変化させていった際に、徐々に正例に分類される出力は増えていきますが、モデルが全く予測できない場合でランダムに予測しているような場合は、ROC 曲線は直線となります。
完全に予測できるようなモデルの場合は、上辺と左辺に一致するような折れ線になります。
AUC (Area under the curve)
ROC 曲線より下部の面積のことを AUC とよびます。AUC が 1.0 に近いほど、モデルの性能が高いといえます。
オッカムの剃刀
「ある事柄を説明するためには、必要以上に多くを仮定するべきでない」とする指針です。
機械学習において、モデルを複雑にすると複雑な表現ができる一方、表現しなくてもよいノイズ部分まで表現してしまい、過学習に陥る可能性があります。
解きたいタスクに対して、実際にモデルをどのくらい複雑にすれば良いかという目安については、赤池情報量規準というものがあります。
特徴量設計
エンコーディング
「男」「女」など、数値で表せないカテゴリを何らかの数値に変換する作業です。
ダミー変数
「男である?」「女である?」といった 0 または 1 の値をとる二値変数です。