概要
こちらのページで使い方を把握した AWS Glue をこちらのページで使い方を把握した AWS Lambda から起動するようにすると、大規模データの ETL 処理を Job 引数やエラー時のハンドリングを含めて柔軟に行うことができます。Glue と Lambda で利用する言語はどちらも Python であるとして、簡単な連携方法について記載します。
ETL 対象となる S3 データソースの準備
こちらのページでは s3.json という一つのファイルを Crawler に指定しました。今回は以下のように日付毎にフォルダ分けされており、各日付のフォルダには二種類のファイルが存在しているとします。
$ aws s3 ls --recursive s3://my-bucket-20171124/
2017-12-03 00:56:39 140 20171201/filetype_a.json
2017-12-03 00:56:43 140 20171201/filetype_b.json
2017-12-03 00:56:45 141 20171202/filetype_a.json
2017-12-03 00:56:48 141 20171202/filetype_b.json
$ aws s3 cp s3://my-bucket-20171124/20171202/filetype_a.json -
{"pstr_a":"fff","pint_a":6}
{"pstr_a":"ggg","pint_a":7}
{"pstr_a":"hhh","pint_a":8}
{"pstr_a":"iii","pint_a":9}
{"pstr_a":"jjj","pint_a":10}
Crawler の設定で filetype_b.json を除外するように設定してみます。
- Include path →
s3://my-bucket-20171124/ - Exclude patterns (複数指定可能) →
**/filetype_b.json - Prefix added to tables (optional) → 未指定
今回は以下のように複数の Partition を含む一つのテーブルが作成できました。
- Name:
my_bucket_20171124 - Classification:
json - Location:
s3://my-bucket-20171124/
テーブルを利用する際に partition_0 として 20171201 や 20171202 の値を取得できます。
| Column name | Data type |
|---|---|
| pstr_a | string |
| pint_a | int |
| partition_0 | string |
Job の登録
IAM ロールの設定などを適切に行ったうえで、以下のような Job を登録します。partition_0 を Job 引数として設定できるようにしています。
- Max concurrency: 1 (Job の多重起動を防止したい場合)
- Job parameters
- Key:
--day_partition_key, Value:partition_0 - Key:
--day_partition_value, Value:99991231(仮の値です。Run job する際に必要な値を指定)
- Key:
- Job Bookmarks: Disable (前回 Job 実行時に正常処理したデータは処理しないようにできます。bookmark はコンソール等から手動で reset できます)
getResolvedOptions で Job parameters を取得できます。取得した partition 情報は filter 等で利用します。
s3://my-glue-scripts/sample_etl.py
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import udf
from pyspark.sql.functions import desc
# AWS Glue を操作するオブジェクト
glueContext = GlueContext(SparkContext.getOrCreate())
spark = glueContext.spark_session
# Job の初期化
args = getResolvedOptions(sys.argv, [
'JOB_NAME',
'day_partition_key',
'day_partition_value'])
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# S3 からデータを取得 (filter で日付を限定)
srcS3 = glueContext.create_dynamic_frame.from_catalog(
database = 'mygluedb',
table_name = 'my_bucket_20171124')
srcS3 = srcS3.filter(lambda r: r[args['day_partition_key']] == args['day_partition_value'])
# 情報を表示
print 'Count:', srcS3.count()
srcS3.printSchema()
srcS3.toDF().show()
# S3 から取得したデータを、加工せずにそのまま S3 に CSV フォーマットで出力
srcS3 = srcS3.toDF()
srcS3 = srcS3.repartition(1) # S3 出力に備えて RDD 分割数を 1 に強制変更
srcS3 = DynamicFrame.fromDF(srcS3, glueContext, 'srcS3')
glueContext.write_dynamic_frame.from_options(
frame = srcS3,
connection_type = 's3',
connection_options = {
'path': 's3://my-glue-outputs/%s/' % args['day_partition_value']
},
format = 'csv')
# Job を終了
job.commit()
AWS Glue コンソールから手動で Run job して --day_partition_value として 20171201 を指定すると以下のような出力ファイルが得られます。
$ aws s3 cp s3://my-glue-outputs/20171201/run-1512243580486-part-r-00000 -
pstr_a,pint_a,partition_0
aaa,1,20171201
bbb,2,20171201
ccc,3,20171201
ddd,4,20171201
eee,5,20171201
Lambda 関数の登録
boto3 を import して Job を start できます。Lambda 関数で利用する IAM ロールには以下のようなポリシーを付与します。登録した Lambda 関数のトリガーに CloudWatch 定期実行イベントを登録することで、AWS Glue 標準の機能と比較して、より柔軟に定期実行することができます。また、Job 失敗時の対応処理を記述した Lambda 関数を登録することでエラーハンドリングも行えます。
my-glue-lambda-role-20171124
LambdaAWSLambdaBasicExecutionRoleAWSGlueServiceRole
lambda_function.py
# -*- coding: utf-8 -*-
import boto3
glue = boto3.client('glue')
def lambda_handler(event, context):
response = glue.start_job_run(
JobName = 'my-job-20171124',
Arguments = {
'--day_partition_key': 'partition_0',
'--day_partition_value': '20171201'
})
return response
ETL 処理単位について
今回のように Table partition を filter する目的で Job 引数を利用する場合、S3 から一旦すべての Table データが取得されてから filter されます。そのため、例えば Daily バッチ処理 ETL で日付を指定する場合、昨日までのデータがすべて読み込まれてしまい低速になります。このような場合は Daily バッチ処理 ETL として、Job だけでなく Crawler も実行して Table を新規に作成します。その際、Crawler 数や Table 数には制限値が存在することに注意します。
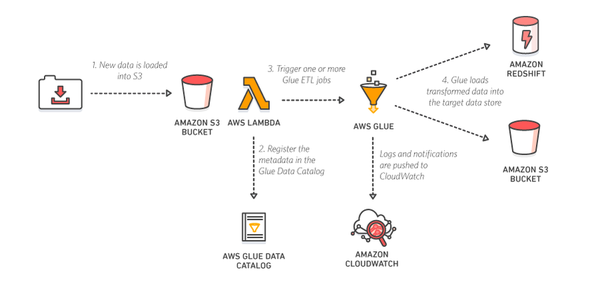
- Lambda 関数で YYYYMMDD の S3 フォルダをクロールする Glue Crawler を登録
- Lambda 関数で Crawler を実行してカタログ Table を生成
- Lambda 関数で Job 引数として新規作成された Table 名を指定して Job を実行
- Job 実行時は新規作成された Table からデータを取得するため、別 Table 内の昨日のデータは取得されずに無駄がない
Athena と QuickSight の利用 (参考情報)
AWS Glue のカタログ Table は Amazon Athena で SQL を発行したり、QuickSight で可視化できます。本ページの目的とは直接関係ありませんが、Lambda から実行した Job によって出力された S3 上のファイルをそれぞれのサービスから利用してみます。
S3 上の ETL 結果に対して Athena クエリを発行
ETL 結果である必要はありませんが、Athena を用いると AWS Glue の Crawler で生成された Glue カタログ Table に対して SQL を発行できます。Crawler には適切な IAM ロールの設定が必要です。
- Include path: s3://my-glue-outputs
- Database: mygluedb
作成された Table で partition_0 の列が複数発生しているため、どちらかの名称をコンソール上の Edit schema から変更します。
| Column name | Data type | Key |
|---|---|---|
| pstr_a | string | |
| pint_a | bigint | |
| partition_0 → date | bigint | |
| partition_0 | string | Partition (0) |
Athena から Table に対して以下のようなクエリを発行します。
SELECT * FROM "mygluedb"."my_glue_outputs";
Athena の Settings で設定した Query result location の S3 に結果ファイルが生成されます。
$ aws s3 cp s3://aws-athena-query-results-123412341234-us-west-2/Unsaved/2017/12/03/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx.csv -
"pstr_a","pint_a","date","partition_0"
"pstr_a",,,"20171201"
"aaa","1","20171201","20171201"
"bbb","2","20171201","20171201"
"ccc","3","20171201","20171201"
"ddd","4","20171201","20171201"
"eee","5","20171201","20171201"
"pstr_a",,,"20171202"
"fff","6","20171202","20171202"
"ggg","7","20171202","20171202"
"hhh","8","20171202","20171202"
"iii","9","20171202","20171202"
"jjj","10","20171202","20171202"
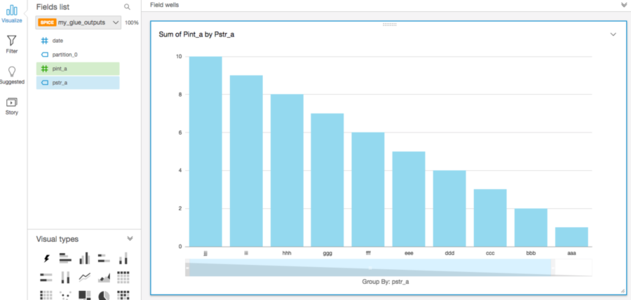
S3 上の ETL 結果を QuickSight で可視化
様々な取り込み方法が選択できますが、例えば AWS Glue の Crawler で生成された Glue カタログ Table を QuickSight に取り込むことができます。QuickSight に対して以下の権限を付与します。IAM ロールと Customer managed な AWSQuickSightS3Policy が生成されます。
- Amazon Athena (Enables QuickSight access to Amazon Athena databases)
- Amazon S3 / my-glue-outputs バケット
こちらのページにしたがって、Create a Data Set から Athena を選択します。Data source name を my-data-source-20171203 等と指定したうえでカタログ Table を設定するだけで、以下のようなグラフが得られます。初回設定時は、QuickSight の無料枠が利用できるリージョンは一つだけしか選択できないことにも注意します。