






概要
G検定のシラバスにおける、強化学習および深層強化学習について記載します。
強化学習
方策 (policy)
強化学習で達成したいことは、報酬和を最大にする方策 (policy) $\pi$ を学習することです。
状態 $S$、行動 $A$ を $[0, 1]$ の確率に変換します。
$$\pi: A \times S \rightarrow [0, 1] \\ \pi(a, s) = Pr(a_t = a | s_t = s) $$
後述の ε-greedy 方策における ε 等、方策はパラメータを持ちます。
バンディットアルゴリズム
強化学習において、方策 (policy) には「活用」と「探索」という概念があります。
- 活用 (exploitation)
- 現在知っている情報から、報酬が最大となるような行動を選びます。
- 探索 (exploration)
- 現在知っている情報以外の情報を獲得するための行動を選びます。
- 学習のある時点で得られた方策のみを用いて行動選択すると、局所解に陥る可能性があります。
- これを回避するために、学習した情報を無視して、ランダムに行動選択することを「探索」とよびます。
バンディットアルゴリズムでは、活用と探索のバランスを取ろうとします。具体的には以下のような手法があります。
- ε-greedy 方策
- 基本的に活用を選択して、一定確率 ε で探索します。
- UCB 方策
マルコフ決定過程モデル
「現在の状態 $s_t$ から将来の状態 $s_{t+1}$ に遷移する確率は、現在の状態 $s_t$ のみに依存し、それより過去の状態には一切依存しない」という性質をマルコフ性とよびます。
状態遷移にマルコフ性を仮定したモデルを、マルコフ決定過程とよびます。
強化学習において、環境の状態遷移はマルコフ性を持つとして扱われることが一般的です。
強化学習の手法の分類
強化学習の手法は、以下のように分けられます。
- 「モデルベース」 → 環境の情報が完全に手に入るときに用います。
- 方策ベース
- 価値ベース
- 「モデルフリー」
- 方策ベース → 「方策勾配法」が該当します。
- 価値ベース → 方策を固定して、行動を選択します。間接的に方策が改善されます。
モデルベースの手法
「状態遷移確率」と「報酬関数」の二つを合わせて「モデル」とよぶことがあります。
モデルが既知であるとは、環境に対する情報が完全であるということになります。
最適価値関数を求めて報酬和を最大化します。
- 状態遷移確率
- ある状態 $s_i$ である行動 $a$ を選んだとき、別のある状態 $s_j$ に遷移する確率です。
- 報酬関数
- ある状態 $s_i$ である行動 $a$ を選んだとき、得られる報酬 $r$ を出力する関数です。
モデルフリーの方策ベースの手法
方策 (policy) $\pi$ が持つパラメータが $\theta$ であるとします。
方策 $\pi(\theta)$ では、ある行動を取る確率を以下のように表現できるとします。
$$p(\theta) = p^{\pi_{\theta}} $$
パラメータ $\theta$ を変化させることを繰返して、報酬和を最大化する手法です。方策を直接的に探索しています。
「方策勾配法」は「モデルフリーの方策ベースの手法」に該当します。
- 一連の行動を行い、得られた報酬から方策を評価して、方策勾配を求めます。
- 方策勾配が分かれば、方策を更新すべき方向が分かります。
- ロボットアームの行動など、連続値を扱う必要のある行動にも対応できます。
モデルフリーの価値関数ベースの手法
- 方策を固定します。
- 価値の高い状態に遷移するように行動を選択します。
- ある状態に対してある行動を取った場合に得られる期待値を算出します。
- 得られる報酬和を最大化します。
- Q 学習などが該当します。
Q 学習
「モデルフリー」の「価値関数ベース」の強化学習アルゴリズムです。
「価値関数」としては、以下の「Q値」を扱います。
「Q値」は、ある状態においてある行動を取った場合に、その後に最終的に得られる報酬和の期待値、を出力する関数です。Q 学習では Q 値を最適化します。
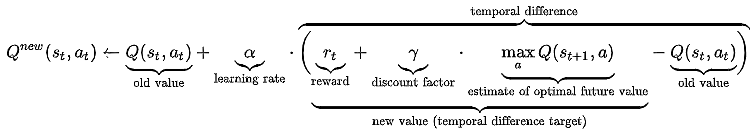
以下の二つの部分から成ります。
- 「Q値」の推定 (価値推定) を行なう部分。
- $a_t$ によって遷移する状態は $s_{t+1}$ です。$Q(s_t, a_t)$ を推定するにあたり、現在推定されている $Q(s_{t+1}, a_{t+1})$ が最大となるような状態 $a_{t+1}$ を選択するのが良いであろうと仮定します 。
- $\alpha$ は学習率です。
- 後述の DQN では、「Q値」をニューラルネットワークで表現して推定します。
- 推定した価値を参考にして行動選択する部分。
SARSA
SARSA (State–action–reward–state–action) は、Q 学習と同様に「Q 値」を最適化するアルゴリズムの一つです。
$$Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha (r_t + \gamma Q(s_{t+1}, a_{t+1}) - Q(s_t, a_t)) $$
Q 学習と異なり、$Q(s_t, a_t)$ の更新時には $Q(s_{t+1}, a_{t+1})$ が最大となるような $a_{t+1}$ を選択するとは仮定しません。
その代わり、実際にエージェントに $a_{t+1}$ を選択させて、その結果を用います。
"State–action–reward–state–action" という名称は、更新時に必要な要素であり、"action" 二つはそれぞれ $a_t$ と $a_{t+1}$ を意味しています。
REINFORCE
「モデルフリーの方策ベースの手法」である「方策勾配法」をベースとした、具体的なアルゴリズムの一つです。
Actor-Critic
「価値関数ベース」および「方策ベース」の考え方を組み合わせた手法の一つです。
行動を決める Actor と方策を評価する Critic から成ります。
A3C (Asynchronous Advantage Actor-Critic)
- Actor-Critic の応用手法の一つです。
- 2016年に DeepMind から発表されました
深層強化学習
ニューラルネットワークを用いて、状態の重要な情報のみを縮約表現します。状態数が多い問題に対しても強化学習が適用できるようになりました。
- 深層学習は「特徴表現学習」を行なうものです。
- 深層強化学習では「特徴表現学習」を指して「状態表現学習」とよぶことがあります。
Deep Q Network (DQN)
- 強化学習の手法の一つ「Q 学習」における、「Q 値 (Q 関数)」をニューラルネットワークで表現します。
- ニューラルネットワークの「入力」は「状態」です。
- 出力層の各ノードは、各行動の価値となります。
- DQN における、Q 値を推定する部分以外の行動選択の部分は、Q 学習で同じです。
Experience replay
- 「状態、行動、報酬」を replay buffer に記録しておき、replay buffer からランダムに取り出して後の遷移で用いる手法です。
- 重みの更新は状態遷移に強い相関を受けるため安定しませんが、Experience replay によってこれを安定化させます。
Dueling network
Q 関数をニューラルネットワークで近似する際に、状態のみから計算できる部分と、行動のみから計算できる部分、を別々に計算します。
Reward clipping
- ニューラルネットワークの重みは報酬の値に大きく影響を受けます。
- 報酬の値を「1, -1, 0」のみに限定したり $[-1, 1]$ の範囲に限定することで、学習を安定化させる手法です。
- 報酬の大小を区別できなくなる、というデメリットはあります。
Double DQN
- Q 関数は、次の状態の Q 関数の値が最大になるように更新されます。そのため、誤差の上方向に影響を受けます。
- これを防ぐために、「オンラインネットワーク」と「ターゲットネットワーク」を用います。
Categorical DQN
- Q 関数は、ある状態とある行動により、この後に得られる報酬和の期待値 (期待収益) です。
- 期待収益を離散確率分布とすることで、学習を安定させます。
- 期待収益を離散確率分布とすることで、期待収益の分散を表現します。
Rainbow
- Double DQN
- Prioritized Experience Replay
- Dueling network
- Categorical DQN
- Noisy network
等をすべて組み合わせた手法です。
OpenAI Five
- マルチエージェント強化学習を、深層学習で行なうゲーム AI の一つです。
- 複数エージェントによる強化学習です。
- 2018 年に発表されました。
- LSTM が用いられています。
AlphaStar
- マルチエージェント強化学習を、深層学習で行なうゲーム AI の一つです。
- 複数エージェントによる強化学習です。
- AlphaGo を開発した DeepMind 社によって、2019 年に発表されました。
- StarCraft というゲームを攻略します。
残差強化学習
モデル化できていない、現実世界に残存する部分を強化学習で学習する手法です。
2019年に、プリンストン大学や Google 等のチームが、TossingBot という研究を発表しました。
AlphaGo
入力である「ある盤面」は盤面の画像であり、ネットワークの学習時には CNN を用います。
2016 年に世界的なトップ騎士であるイ・セドルに囲碁で勝利しました。
教師あり学習フェーズ
二つのネットワークを学習させます。
- SL Policy (Supervised Learning Policy Network)
- 人間の棋譜を教師データとします。
- ある盤面から、次の盤面を予測します。
- Rollout Policy
- 人間の棋譜を教師データとします。
- ある盤面から、次の盤面を予測します。
- 予測性能を下げる代わりに計算を高速化します。
強化学習フェーズ
SL Policy を強化学習によって RL Policy にします。
- Reinforcement Learning Policy Network (RL Policy)
- SL Policy 同士を戦わせます。
- 勝った側が打った手を方策勾配法で強化していきます。
- 片方を RL Policy として強化し続けます。
RL Policy を二つ用意します。
- Value Network
- RL Policy は最善手を打つと仮定します。
- RL Policy 同士を戦わせた結果を、各盤面の勝率として扱うことができます。
- ある盤面から、その盤面における勝率を予測するネットワークを Value Network とよびます。
- 教師データは、RL Policy 同士を戦わせて得られた棋譜です。
Value Network を、モンテカルロ木探索 (MCTS) のアルゴリズムにおける、行動選択部分に組込みます。
SL Policy と Value Network で行動選択を行います。
モンテカルロ木探索
ある状態から行動選択を繰り返して報酬和を計算する、ということを複数回行った後、報酬和の平均値を状態の価値とする、価値推定方法です。
AlphaGo Zero
人間の棋譜データを用いた教師あり学習は行いません。AlphaGo を上回る強さに到達しています。
AlphaGo では Policy Network、Rollout Policy、Value Network の三つを学習していましたが、AlphaGo Zero では、これらを一つのネットワークにまとめています。簡潔なアーキテクチャとなっており、学習にかかる時間も短くなっています。
Alpha Zero
囲碁以外のゲームにおいても、人間のトッププレイヤーを越えていた多くのゲーム AI を圧倒する性能を持つようになりました。
人間の棋譜データを用いた教師あり学習は行いません。