- Looker から Snowflake への OAuth 接続
- Looker (Google Cloud core) 30日間 フリートライアル設定
- AWS 落穂拾い (Security)
- AWS 落穂拾い (Storage)
- マイクロマウス

概要
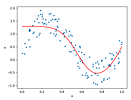
自動微分というアルゴリズムによって関数の微分値を求める例を記載します。本ページでは、一階微分を対象としており、高階微分は考えません。また簡単のため、関数の出力は一つのテンソルであり、入力となる一つ以上のテンソルおよび出力となる一つのテンソルの階数は零である例を考えます。
更に、関数は、微分可能な関数からなる合成関数であることを仮定します。これは自動微分の応用先の一つである、ディープラーニングにおけるニューラルネットワークの性質の一つです: Chainer Tutorial / ニューラルネットワークの基礎 / 誤差逆伝播法(バックプロパゲーション)
PyTorch による例
PyTorch はテンソル (多次元配列) を扱うことができるライブラリで、ディープラーニングなどに用いられます。スカラは零階のテンソル、ベクトルは一階のテンソル、行列は二階のテンソルです。
以下のようにインストールできます。
python3 -m pip install torch torchvision
NVIDIA GPU が利用できる環境であれば以下の値が True になります。
python3 -m IPython
In [1]: import torch
...: torch.cuda.is_available()
Out[1]: False
PyTorch には自動微分が実装されており、以下のように利用できます。入力となる二つのテンソル $x$ と $y$ の階数は零です。出力となる一つのテンソル $z$ の階数も零です。
import torch
x = torch.tensor(1.0, requires_grad=True)
y = torch.tensor(1.0, requires_grad=True)
z = x ** 2 + y ** 2
z.backward()
print(x.grad, y.grad) # tensor(2.) tensor(2.)
数式微分を考えても $x^2 + y^2$ の $x$ および $y$ に関する偏微分はどちらも 2 となるため、上記結果は正しいことが分かります。必要に応じて数値微分で自動微分の結果を検証することもできます。
自動微分のアルゴリズム
『ゼロから作るDeep Learning ❸』のソースコードはこちらで公開されており、内容を確認すると、自動微分のアルゴリズムは以下のようになっていることが分かります。
main.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
from autograd.variable import Variable
import numpy as np
def Main():
# 零階のテンソルを二つ入力します。
x = Variable(np.array(1.0))
y = Variable(np.array(1.0))
# 微分可能な関数からなる合成関数です。
# すべて一つのテンソルを出力しています。
for z in (Sphere(x, y),
Matyas(x, y),
Goldstein(x, y)):
# 前のループで格納された、微分結果を忘れます。
x.ClearGrad()
y.ClearGrad()
# バックプロパゲーションによって微分します。
z.Backward()
# 結果を確認します。
print(x.GetGrad(), y.GetGrad())
def Sphere(x, y):
z = x ** 2 + y ** 2
return z
def Matyas(x, y):
z = 0.26 * (x ** 2 + y ** 2) - 0.48 * x * y
return z
def Goldstein(x, y):
a = 1 + (x + y + 1) ** 2 * (19 - 14 * x + 3 * x ** 2 - 14 * y + 6 * x * y + 3 * y ** 2)
b = 30 + (2 * x - 3 * y) ** 2 * (18 - 32 * x + 12 * x ** 2 + 48 * y - 36 * x * y + 27 * y ** 2)
z = a * b
return z
if __name__ == '__main__':
Main()
autograd/__init__.py
Python パッケージのために必要な空ファイルです。
# -*- coding: utf-8 -*-
autograd/variable.py
__repr__ や __len__ は Python の特殊メソッドです。同様に __add__ や __mul__ も特殊メソッドで、これらは Python における演算子オーバーロードのために用いられます。
# -*- coding: utf-8 -*-
import numpy as np
class Variable(object):
def __init__(self, data, name=None):
if data is not None:
if not isinstance(data, np.ndarray):
raise TypeError('{} is not supported'.format(type(data)))
self.__name = name
self.__data = data # テンソル
self.__grad = None # テンソル
self.__creator = None # この変数を出力した Function
self.__generation = 0 # この変数の世代
def __repr__(self):
if self.__data is None:
return 'Variable(None)'
p = str(self.__data).replace('\n', '\n' + ' ' * 9)
return 'Variable(' + p + ')'
def __len__(self):
return len(self.__data)
def __neg__(self):
return neg(self)
def __add__(self, other):
return add(self, other)
def __radd__(self, other):
return add(self, other)
def __mul__(self, other):
return mul(self, other)
def __rmul__(self, other):
return mul(self, other)
def __sub__(self, other):
return sub(self, other)
def __rsub__(self, other):
return sub(other, self) # 引数の順番を逆に設定
def __truediv__(self, other):
return div(self, other)
def __rtruediv__(self, other):
return div(other, self) # 引数の順番を逆に設定
def __pow__(self, other):
return pow(self, other)
# NumPy に実装されている演算子オーバーロードよりも
# Variable クラスに実装されている演算子オーバーロードを
# 優先させるための設定。
# https://numpy.org/doc/stable/reference/arrays.classes.html#numpy.class.__array_priority__
__array_priority__ = 200
def GetName(self):
return self.__name
def GetData(self):
return self.__data
def GetCreator(self):
return self.__creator
def SetCreator(self, func):
self.__creator = func
# 変数の「世代」は、変数を作り出した関数の「世代」に 1 を加えたものとしています。
self.__generation = func.GetGeneration() + 1
def GetGeneration(self):
return self.__generation
def GetGrad(self):
return self.__grad
def SetGrad(self, grad):
self.__grad = grad
def ClearGrad(self):
self.__grad = None
def Backward(self, retainGrad=False):
if self.__grad is None:
# バックプロパゲーションの起点となる変数の微分値を 1 に設定。
self.__grad = np.ones_like(self.__data)
funcs = []
seenSet = set()
def AddFunc(f):
if f in seenSet:
return
funcs.append(f)
seenSet.add(f)
funcs.sort(key=lambda x: x.GetGeneration())
AddFunc(self.__creator)
while len(funcs) > 0:
# 同じ変数を異なる複数の関数に入力した場合への対応。
# e.g.
# --> x --> Square(x) : a --> Add(a, b) : c
# --> Exp(x) : b -/
# 世代の大きい関数から順に処理します。
f = funcs.pop()
gys = [output().GetGrad() for output in f.GetOutputs()]
gxs = f.Backward(*gys)
if not isinstance(gxs, tuple):
gxs = gxs,
for x, gx in zip(f.GetInputs(), gxs):
if x.GetGrad() is None:
x.SetGrad(gx)
else:
# 同じ変数を同じ関数に複数回数入力した場合への対応
# e.g. Add(x, x)
x.SetGrad(x.GetGrad() + gx)
if x.GetCreator() is not None:
AddFunc(x.GetCreator())
if retainGrad:
return
# バックプロパゲーションの処理が完了した関数から出力された変数の微分値は、
# 今後の処理で不要なため、オプションが指定されていない場合はメモリ解放のために忘れます。
for y in f.GetOutputs():
y().SetGrad(None)
from .function import neg
from .function import add
from .function import mul
from .function import sub
from .function import div
from .function import pow
autograd/function.py
弱参照 weakref によって、循環参照によるメモリリークを回避しています。
# -*- coding: utf-8 -*-
import numpy as np
import weakref
from .variable import Variable
class Function(object):
def __init__(self):
self.__inputs = None
self.__outputs = None
self.__generation = None
def __call__(self, *inputs):
inputs = [AsVariable(x) for x in inputs]
xs = [x.GetData() for x in inputs]
ys = self.Forward(*xs)
if not isinstance(ys, tuple):
ys = ys,
outputs = [Variable(AsArray(y)) for y in ys]
# 関数の世代を、入力変数の世代の最大値、として設定します。
self.__generation = max([x.GetGeneration() for x in inputs])
for output in outputs:
output.SetCreator(self)
self.__inputs = inputs
self.__outputs = [weakref.ref(output) for output in outputs] # 弱参照
return outputs if len(outputs) > 1 else outputs[0]
def GetInputs(self):
return self.__inputs
def GetOutputs(self):
return self.__outputs
def GetGeneration(self):
return self.__generation
def Forward(self, x):
raise NotImplementedError()
def Backward(self, gy):
raise NotImplementedError()
def AsArray(x):
if np.isscalar(x):
return np.array(x)
return x
def AsVariable(obj):
if isinstance(obj, Variable):
return obj
return Variable(obj)
class Neg(Function):
def Forward(self, x):
return -x
def Backward(self, gy):
return -gy
class Add(Function):
def Forward(self, x0, x1):
y = x0 + x1
return y
def Backward(self, gy):
return gy, gy
class Mul(Function):
def Forward(self, x0, x1):
y = x0 * x1
return y
def Backward(self, gy):
x0 = self.GetInputs()[0].GetData()
x1 = self.GetInputs()[1].GetData()
return gy * x1, gy * x0
class Sub(Function):
def Forward(self, x0, x1):
y = x0 - x1
return y
def Backward(self, gy):
return gy, -gy
def Div(Function):
def Forward(self, x0, x1):
y = x0 / x1
return y
def Backward(self, gy):
x0 = self.GetInputs()[0].GetData()
x1 = self.GetInputs()[1].GetData()
gx0 = gy / x1
gx1 = gy * (-x0 / x1 ** 2)
return gx0, gx1
class Pow(Function):
def __init__(self, c):
self.__c = c
def Forward(self, x):
y = x ** self.__c
return y
def Backward(self, gy):
x = self.GetInputs()[0].GetData()
c = self.__c
gx = c * x ** (c - 1) * gy
return gx
class Exp(Function):
def Forward(self, x):
return np.exp(x)
def Backward(self, gy):
x = self.GetInputs()[0].GetData()
gx = np.exp(x) * gy
return gx
def neg(x):
return Neg()(x)
def add(x0, x1):
x0 = AsArray(x0)
x1 = AsArray(x1)
return Add()(x0, x1)
def mul(x0, x1):
x0 = AsArray(x0)
x1 = AsArray(x1)
return Mul()(x0, x1)
def sub(x0, x1):
x0 = AsArray(x0)
x1 = AsArray(x1)
return Sub()(x0, x1)
def div(x0, x1):
x0 = AsArray(x0)
x1 = AsArray(x1)
return Div()(x0, x1)
def pow(x, c):
return Pow(c)(x)
def exp(x):
return Exp()(x)
実行例
$ python3 main.py
2.0 2.0
0.040000000000000036 0.040000000000000036
-5376.0 8064.0
確かに PyTorch の出力結果と一致することが分かります。
ヤコビ行列について
$(y_1, ..., y_m)$ それぞれが $(x_1, ..., x_l)$ の関数であり、$y_j$ は $x_i$ で偏微分可能である場合について、以下の行列をヤコビ行列とよびます。ヤコビ行列の行列式をヤコビアンとよびます。
$$J_{xy} = \left( \begin{array}{rr} \frac{\partial y_1}{\partial x_1} & ... & \frac{\partial y_1}{\partial x_l} \\ ... & ... & ... \\ \frac{\partial y_m}{\partial x_1} & ... & \frac{\partial y_m}{\partial x_l} \\ \end{array} \right) $$
ヤコビ行列は例えば関数の一次近似を扱う場合に利用できます。具体例として、こちらのページで扱った、ロボットアームのマニピュレータの位置姿勢 $x_1, x_2, x_3, \phi_1, \phi_2, \phi_3$ は関節値 $\theta_1, ..., \theta_l$ の関数です。マニピュレータの位置姿勢はヤコビ行列を用いて以下のように近似できます。
$$\left( \begin{array}{c} x_1(\vec{\theta}) \\ x_2(\vec{\theta}) \\ x_3(\vec{\theta}) \\ \phi_1(\vec{\theta}) \\ \phi_2(\vec{\theta}) \\ \phi_3(\vec{\theta}) \end{array} \right) = \vec{y}(\vec{\theta}) \simeq \vec{y}(\vec{\theta_0}) + J(\vec{\theta_0}) (\vec{\theta} - \vec{\theta_0}) $$
連鎖律 (Chain Rule) について
さらに $(z_1, ..., z_n)$ それぞれが $(y_1, ..., y_m)$ の関数であり、$z_k$ は $y_j$ で偏微分可能である場合について、ヤコビ行列を $J_{yz}$ とします。
$$J_{yz} = \left( \begin{array}{rr} \frac{\partial z_1}{\partial y_1} & ... & \frac{\partial z_1}{\partial y_m} \\ ... & ... & ... \\ \frac{\partial z_n}{\partial y_1} & ... & \frac{\partial z_n}{\partial y_m} \\ \end{array} \right) $$
このとき、$(z_1, ..., z_n)$ の $(x_1, ..., x_l)$ を用いた一次近似は以下のようになります。
$$\begin{eqnarray} \vec{z}(\vec{x}) &\simeq& \vec{z}(\vec{x_0}) + J_{xz}(\vec{x_0}) (\vec{x} - \vec{x_0}) \\ &=& \vec{z}(\vec{x_0}) + J_{yz}(\vec{y_0}) J_{xy}(\vec{x_0}) (\vec{x} - \vec{x_0}) \\ \end{eqnarray} $$
$J_{xz} = J_{yz} J_{xy}$ の部分は連鎖律 (Chain Rule) とよばれています。
$$\frac{\partial z_k}{\partial x_i} = \sum_{j=1}^{m} \frac{\partial z_k}{\partial y_j} \frac{\partial y_j}{\partial x_i} $$
さきほどの自動微分のサンプルプログラムにおけるバックプロパゲーションのアルゴリズムでは、この Chain Rule が利用されています。例えば、乗算 class Mul の Backward 関数は以下のようになっています。
class Mul(Function):
def Forward(self, x0, x1):
y = x0 * x1
return y
def Backward(self, gy):
x0 = self.GetInputs()[0].GetData()
x1 = self.GetInputs()[1].GetData()
return gy * x1, gy * x0
一般性を失うことなく $k$ が 1 の場合を考えます。例えば以下のような合成関数 $z_1(x_1, x_2)$ の $y_2(x_1, x_2)$ が $x_1$ と $x_2$ の乗算である場合、
$$\begin{eqnarray} z_1(x_1, x_2) &=& y_1(x_1, x_2) + y_2(x_1, x_2) \\ &=& y_1(x_1, x_2) + x_1 x_2 \end{eqnarray} $$
連鎖律は以下のようになります。
$$\begin{eqnarray} \frac{\partial z_1}{\partial x_1} &=& \frac{\partial z_1}{\partial y_1} \frac{\partial y_1}{\partial x_1} + \frac{\partial z_1}{\partial y_2} \frac{\partial y_2}{\partial x_1} \\ &=& \frac{\partial z_1}{\partial y_1} \frac{\partial y_1}{\partial x_1} + \frac{\partial z_1}{\partial y_2} x_2 \end{eqnarray} $$
$$\begin{eqnarray} \frac{\partial z_1}{\partial x_2} &=& \frac{\partial z_1}{\partial y_1} \frac{\partial y_1}{\partial x_2} + \frac{\partial z_1}{\partial y_2} \frac{\partial y_2}{\partial x_2} \\ &=& \frac{\partial z_1}{\partial y_1} \frac{\partial y_1}{\partial x_2} + \frac{\partial z_1}{\partial y_2} x_1 \end{eqnarray} $$
$\frac{\partial z_1}{\partial y_2} x_2$ および $\frac{\partial z_1}{\partial y_2} x_1$ の部分が def Backward の実装内容です。