- Looker から Snowflake への OAuth 接続
- Looker (Google Cloud core) 30日間 フリートライアル設定
- AWS 落穂拾い (Security)
- AWS 落穂拾い (Storage)
- マイクロマウス
- 概要
- シグモイド関数を用いた学習における勾配消失について
- 分類問題の出力層で用いられる活性化関数について
- tanh とシグモイド関数の関係
- 損失関数の最適化に用いる手法
- 過学習を防ぐための手法
- データの白色化
- 重みパラメータの初期値
- バッチ正規化
- CNN (Convolutional Neural Network)
- データ拡張 (Data Augmentation)
- 転移学習とファインチューニング
- RNN (Recurrent Neural Network)
- LSTM
- GRU (Gated Recurrent Unit)
- RNN Encoder-Decoder
- Attention 機構を持つ seq2seq モデル
- 事前学習
- バーニーおじさんのルール

概要
G検定のシラバスにおける「ディープラーニングの概要」および「ディープラーニングの手法」に関連する事項を記載します。
シグモイド関数を用いた学習における勾配消失について
ディープラーニングで用いられる活性化関数の一つに、シグモイド関数があります。
$$y = \frac{1}{1 + \exp(-x)} $$
こちらのページでは、シグモイド関数を用いて、以下のような合成関数を考えました。簡単のため、隠れ層の次元数を $H = 1$ としています。
$$\begin{eqnarray} f(x, w, b) &=& w x + b \\ g(x) &=& \frac{1}{1 + \exp(-x)} \end{eqnarray} $$
$y$ が出力、$x$, $w_1$, $w_2$, $b_1$, $b_2$ が入力です。
$$\begin{eqnarray} t &=& f(x, w_1, b_1) \\ u &=& g(t) \\ y &=& f(u, w_2, b_2) \end{eqnarray} $$
ここで、$X_i$ を入力したときに出力が $Y_i$ と近くなるような $w_1$, $w_2$, $b_1$, $b_2$ を、反復法により学習して求めることを考えます。そのために、以下の平均二乗誤差が 0 に近づくような $w_1$, $w_2$, $b_1$, $b_2$ を求めることを考えました。
$$L(w_1, w_2, b_1, b_2) = \frac{1}{N} \sum_{i=0}^N (y_i - Y_i)^2 $$
$L$ は 0 以上の値をとります。$L$ の値が最小となる $w_1$, $w_2$, $b_1$, $b_2$ の値においては、$L$ の傾きが 0 となります。
$L$ の偏微分を求めることができれば、反復法によって、そのような $w_1$, $w_2$, $b_1$, $b_2$ の値を計算することができます。
$L$ の偏微分は、以下のように計算できます。$\partial y_i / \partial w_1$ を求めることができれば良いことが分かります。$w_2$, $b_1$, $b_2$ についても同様です。
$$\begin{eqnarray} \frac{\partial L}{\partial w_1} &=& \frac{1}{N} \frac{\partial}{\partial w_1} \sum_{i=0}^N (y_i^2 - 2 Y_i y_i + Y_i^2) \\ &=& \frac{1}{N} \sum_{i=0}^N (2 y_i \frac{\partial y_i}{\partial w_1} - 2 Y_i \frac{\partial y_i}{\partial w_1}) \\ &=& \frac{2}{N} \sum_{i=0}^N (y_i - Y_i) \frac{\partial y_i}{\partial w_1} \end{eqnarray} $$
$\partial y_i / \partial w_1$ は以下のように計算できます。
$$\begin{eqnarray} \frac{\partial y_i}{\partial w_1} &=& \frac{\partial f(u_i, w_2, b_2)}{\partial w_1} \\ &=& \frac{\partial y_i}{\partial u_i} \frac{\partial u_i}{\partial w_1} + \frac{\partial y_i}{\partial w_2} \frac{\partial w_2}{\partial w_1} + \frac{\partial y_i}{\partial b_2} \frac{\partial b_2}{\partial w_1} \\ &=& \frac{\partial y_i}{\partial u_i} \frac{\partial u_i}{\partial w_1} \\ &=& \frac{\partial y_i}{\partial u_i} \frac{\partial g(t_i)}{\partial w_1} \\ &=& \frac{\partial y_i}{\partial u_i} \frac{\partial g(t_i)}{\partial t_i} \frac{\partial t_i}{\partial w_1} \\ &=& \frac{\partial y_i}{\partial u_i} \frac{\partial u_i}{\partial t_i} \frac{\partial f(x_i, w_1, b_1)}{\partial w_1} \\ &=& \frac{\partial y_i}{\partial u_i} \frac{\partial u_i}{\partial t_i} \left( \frac{\partial t_i}{\partial x_i} \frac{\partial x_i}{\partial w_1} + \frac{\partial t_i}{\partial w_1} \frac{\partial w_1}{\partial w_1} + \frac{\partial t_i}{\partial b_1} \frac{\partial b_1}{\partial w_1} \right) \\ &=& \frac{\partial y_i}{\partial u_i} \frac{\partial u_i}{\partial t_i} \frac{\partial t_i}{\partial w_1} \\ &=& w_2 X_i \frac{\partial g(t_i)}{\partial t_i} \end{eqnarray} $$
シグモイド関数 $g(t)$ の傾きは、$t$ が 0 から大きく離れると 0 になります。
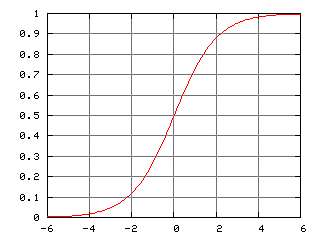
そのため、$\partial y_i / \partial w_1$ の値が小さくなってしまい、反復法による $w_1$ の学習がうまく進まなくなる場合があります。これを勾配消失とよびます。
分類問題の出力層で用いられる活性化関数について
二値分類
「イヌまたはネコ」の二値に画像を分類する問題において、「イヌである確率」が出力 $p$ が得られれば、「ネコである確率」は $1 - p$ となります。
多値分類
0 から 10 の数字に画像を分類する問題において、出力は 0 から 10 の数字それぞれである確率 $p_1, p_2, ..., p_{10}$ となります。
活性化関数
二値分類の問題において、シグモイド関数を出力層で用いることで、$[0, 1]$ の範囲に変換された値を出力できます。
$$p = \frac{1}{1 + \exp(-x)} $$
多値分類の問題においては、こちらのページに記載の活性化関数である、ソフトマックス関数を用いることで、同様に $[0, 1]$ の範囲に変換された値を出力できます。
$$p_i = \frac{\exp(x_i)}{\sum_j \exp(x_j)} $$
tanh とシグモイド関数の関係
双曲線関数の一つである tanh は値の範囲が $(0, 1)$ であり、隠れ層の活性化関数として用いることができます。
シグモイド関数の傾きの最大値が 0.25 であるのに対して、tanh の傾きの最大値は 1.0 です。そのため、シグモイド関数と比較して、隠れ層における勾配消失が発生しにくいという特徴があります。ただし、0近傍を除いては傾きが大きい訳ではないため、根本的な勾配消失問題の解消にはなりません。
$$tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} $$
また、tanh はシグモイド関数 $f(x) = 1 / (1 + e^{-x})$ を用いて表現できます。参考: シグモイド関数の意味と簡単な性質
$$\begin{eqnarray} tanh(x) &=& \frac{2}{1 + e^{-2x}} - 1 \\ &=& 2 f(2x) - 1 \end{eqnarray} $$
損失関数の最適化に用いる手法
最急降下法 (Gradient Descent)
微分値が最も大きくなる方向に学習を進めます。
- 学習用のデータはすべて入力します。バッチ学習。
- すべてのデータにとって最適な方向へのパラメータ学習がなされます。
- 勾配に学習率を掛けて、パラメータを更新します。
SGD (Stochastic Gradient Descent: 確率的勾配降下法)
一部のデータについて、微分値が最も大きくなる方向に学習を進めます。
- 学習用のデータから無作為に $N$ 個だけ取り出して入力します。ミニバッチ学習。$N = 1$ の場合はオンライン学習。
- 確率的に取り出された一部のデータにとって最適な方向へのパラメータ学習がなされます。
- 勾配に学習率を掛けて、パラメータを更新します。
モーメンタム
パラメータの更新時に物理の慣性のようなものを考慮します。勾配の方向に加速や減速を行ったり、摩擦抵抗による減速を行います。
- 勾配を計算するところまでは SGD と同じです。
- 勾配をもとに、慣性 (モーメンタム) を考慮してパラメータを更新します。
具体的な手法には、登場した順番に並べると、以下のようなものがあります。
AdaGrad → AdaDelta → RMSprop → Adam → AdaBound → AMSBound
最適化の手法に Adam を用いた具体的なサンプルコードはこちらです。
過学習を防ぐための手法
Dropout
ニューラルネットワークのパラメータ学習時において、ニューラルネットワークのノードをランダムに無視する手法です。無視されるノードの箇所によって、ニューラルネットワークの形が異なります。
そのため、ドロップアウトを用いると複数のネットワークが同時に学習されることになり、複数のモデルを学習して結果を統合する手法であるアンサンブル学習を行っていると考えることができます。
Early Stopping
テストデータにおける誤差が上昇傾向に転じた時点で、訓練データを用いた学習を打ち切る手法です。
どのような形状のネットワークにも容易に適用できるため、ジェフリー・ヒントンはこれを「Beautiful Free Lunch」と表現しました。
これは、「あらゆる問題に対して性能の良い汎用最適化戦略は理論上不可能である」という、ノーフリーランチ定理に反することを意図した表現です。
ただし、最近の研究では、一度テストデータに対する誤差が増えた後、再度誤差が減っていくという「二重降下現象 (double descent phenomenon)」も確認されています。
データの白色化
白色化
無相関化した $n$ 変量のデータの、各変量を標準化することです。
標準化
平均を 0 に、分散を 1 にすることです。
無相関化
$n$ 変量のデータの共分散を 0 にして相関を無くすことです。主成分分析を利用します。
重みパラメータの初期値
勾配降下法に用いる重みパラメータの初期値は、一様分布や正規分布にしたがう乱数が用いられますが、ディープニューラルネットワークの重みパラメータ学習時は、以下のような工夫がなされます。
- シグモイド関数が活性化関数として用いられている層の、重みパラメータ → Xavier の初期値
- 標準偏差 $\sqrt{1 / n}$ を持つ正規分布
- ReLU 関数が活性化関数として用いられている層の、重みパラメータ → He の初期値
- 標準偏差 $\sqrt{2 / n}$ を持つ正規分布
- ReLU は入力が負の場合に出力が 0 となるため、シグモイド関数の場合と比較して、正規分布の標準偏差は大きく設定されています。
バッチ正規化
各隠れ層の内部で、活性化関数への入力値の正規化を行う手法を「バッチ正規化」とよびます。
隠れ層(中間層): 重みとバイアスを用いた線形変換 → バッチ正規化 → 活性化関数
バッチ正規化を行うと、過学習が起きにくくなることが知られています。
CNN (Convolutional Neural Network)
畳み込み層で学習されるパラメータと、事前に値を設定するハイパーパラメータ
CNN におけるニューラルネットワークの学習では、カーネルの中の数値が学習の対象となる重みです。
カーネルのサイズ、ストライド、パディングは学習前に決定される「ハイパーパラメータ」です。
特徴マップ
カーネルを用いた畳み込み演算がなされた結果を「特徴マップ」とよびます。CNN におけるカーネルは複数設定されます。
畳み込み層では、それぞれのカーネルに対応する特徴マップが得られます。
得られた特徴マップを、次の層の入力画像とします。
プーリング層
特徴マップを 2x2 といった領域毎に分割します。
これらの領域の値の最大値や平均値を計算して、別の特徴マップに変換する処理をプーリングとよびます。
maxプーリングを行なう場合、物体の位置が多少ずれても同じ特徴マップが出力され、同じ特徴量を見つけ出すことができると期待されます。わずかな位置の違いを過学習することを防ぐことができます。
畳み込み層でも同様の結果を得ることは可能ですが、畳み込み層と異なり、プーリング層では学習すべきパラメータがないという特徴があります。
全結合層
畳み込み層とプーリング層で変換された結果の特徴マップは二次元の構造です。
これを分類したいクラス群である一次元に変換するためには、特徴マップを一次元に変換してから全結合層に接続します。
ディープニューラルネットワークではない、多層パーセプトロンとよばれる通常のニューラルネットワークと全結合層は同じ構造をしています。
Global Average Pooling (GAP)
全結合層は重みパラメータを持つため、近年では代わりに Global Average Pooling を用いることが多くなっています。
特徴マップに含まれる値の平均値を、特徴マップに対応する分類したいクラスに対する値として扱います。
更にこの値を Softmax 関数に通すことで、各クラスに分類される確率としての出力となります。
全結合層が持つ重みパラメータを学習する必要がなく、過学習が起きにくくなる等のメリットがあります。
初期の CNN モデル
- ネオコグニトロン: 画像の濃淡を検出する単純型細胞 (S細胞) と、物体の位置変動に影響されずに認識できるようにする複雑型細胞 (C細胞)、の二つの細胞の働きを組み込んだモデルです。1980 年代に福島邦彦によって提唱されました。
- S細胞は畳み込み層に対応します。
- C細胞はプーリング層に対応します。
- LeNet: その後 1998年に「ヤン・ルカン」によって考えられた、畳み込み層とプーリング層 (サブサンプリング層) を交互に組み合せた CNN のモデルです。誤差逆伝搬法によって学習が行われます。
データ拡張 (Data Augmentation)
画像に人工的な加工を行なうことで、データの種類を増やすことができます。これをデータ拡張とよびます。
平行移動、左右上下反転、回転、拡大縮小、一部切り取り、コンストラストの変更、といった処理が該当します。
ただし、データの種類によっては不適切なデータ拡張が存在します。
例えば「6」と「9」の画像を上下反転させることは不適切です。
その他の手法
- Cutout → 画像の一部分に対して、画素値を0にします。
- Random Erasing → 画像の一部分に対して、画素値をランダムにします。
- Mixup → 2枚の画像を合成します。
- CutMix → Cutout と Mixup を組み合わせます。
転移学習とファインチューニング
ニューラルネットワークにおいて、
- 入力層付近では画像に含まれる抽象的な特徴量が学習され、
- 出力層付近では画像に含まれる具体的な特徴量が学習される
ことが知られています。
転移学習およびファインチューニングでは、学習済みモデルの出力層の後に新たな層を追加したり、既存の出力層を置き換えたりすることで、入力層が持つ抽象的なパラメータを使い回すことを考えます。
ただし、学習済みモデルが利用したデータと、今回の学習で用いるデータの関連性が低い場合は、転移学習およびファインチューニングを用いることは不適切です。
転移学習
付け足した層、または置き換えた層のパラメータのみを学習します。
ファインチューニング
付け足した層、または置き換えた層のパラメータを学習することに加えて、学習済みモデル内のパラメータも調整します。
RNN (Recurrent Neural Network)
文章のようなデータでは、ある単語と前後の単語との関係性等を特徴量として扱う必要があります。これら時系列データを扱うためには RNN を用います。
過去の入力による隠れ層の状態が、現在の入力に対する出力の算出時に利用されます。
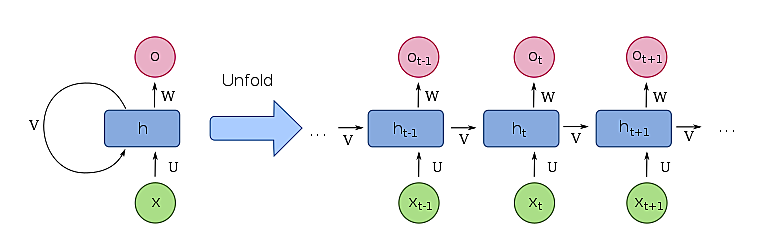
RNN における誤差逆伝搬法は、時系列の新しいデータから順に誤差逆伝搬法を繰返していくことになり、特に「通時的誤差逆伝搬 (BPTT; BackPropagation Through Time)」とよばれます。
そのため、時系列の古いデータほど勾配消失または勾配爆発の問題が発生しやすいという特徴があります。
また、隠れ状態はあくまでも一つであり、それが時間情報をもっているだけであることに注意します。
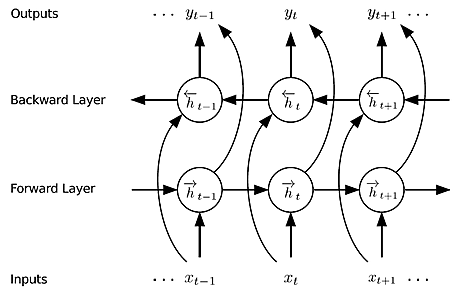
双方向 RNN (BiRNN; Bidirectional RNN)
過去と未来の両方の情報をもとにして出力します。例えば、自然言語処理において単語の品詞を推定したい場合は、過去の単語だけでなく未来の単語の情報も用いた方が精度が上がります。
LSTM
RNN においては、時系列の古いデータに関する勾配消失問題があり、長期にわたって時系列の古いデータの情報を考慮し続けることができません。
また、現時点では重要でなくても将来的には考慮する必要がある重要な情報、を適切に扱うことができず、入力重み衝突、出力重み衝突とよばれます。
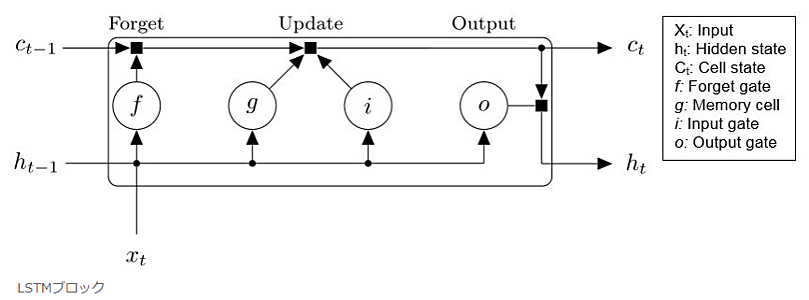
LSTM (Long Short Term Memory) では、これらの問題を解決するために、以下の構造が導入されています。
- CEC (Constant Error Carousel) とよばれる記憶用のセルに、勾配消失が発生しないように Add 演算によって過去の情報を蓄積し続けます。
- 忘却ゲートによって、CEC から情報を削除できます。
- 忘却ゲートは画像において $f$ で表示される箇所ですが、関数としては「シグモイド関数」となります。シグモイド関数の出力である 0 から 1 の値を、CEC からの情報と掛け合せます。
- 入力ゲートによって、CEC に新たに記憶する情報を選択できます。
- 出力ゲートによって、CEC の内容から選択的に情報を出力できます。
GRU (Gated Recurrent Unit)
LSTM には計算量が多いという問題があり、軽量化したモデルの一つが GRU (Gated Recurrent Unit) です。
- 前時刻の隠れ状態から、選択した情報を削除するための、リセットゲート
- 現在時刻のデータと、リセットゲートが通された前時刻の隠れ状態の情報、の二つをもとにした情報から、選択した情報によって隠れ状態を更新する、更新ゲート
を用いた構造となっており、CEC に相当する記憶セルを持ちません。更新ゲートをとおった情報は、隠れ状態の更新、および現在時刻における出力になります。
RNN Encoder-Decoder
seq2seq 問題
RNN (この文脈では LSTM、GRU も含みます) では時系列データから一つの出力が得られます。
自然言語処理の機械翻訳など、出力も時系列データとして得たい場合があります。
これを sequence-to-sequence (seq2seq) 問題とよびます。
RNN Encoder-Decoder
seq2seq 問題を解くために、二つの RNN を結合します。
- 入力となる時系列データを固定長ベクトルに変換する RNN を Encoder、
- Encoder が出力した固定長ベクトルを時系列データに変換する RNN を Decoder
とよびます。
This is a pen → [Encoder] → 固定長ベクトル → [Decoder] → これは 1本の ペン です
機械翻訳において、固定長ベクトルは言語によらない「文脈」です。
Encoder の出力は、Encoder RNN の隠れ層の最後の状態の情報であり、したがって固定長となります。
RNN Encoder-Decoder における Encoder の出力は、入力となる時系列データによらず固定長です。
任意の長さの時系列データを固定長のベクトルに圧縮していると考えることができます。
Image Captioning
RNN の代わりに CNN を Encoder として用いることで、Decoder の RNN と合わせて、Image Captioning を実現できます。入力画像の説明文を出力できます。
Attention 機構を持つ seq2seq モデル
RNN Encoder-Decoder では、長い時系列データが入力となる場合に、固定長ベクトルに情報が入りきらないといった問題が発生します。
そこで、Encoder RNN の隠れ層の最後の状態だけでなく、入力となる時系列データを入力する度に更新される状態すべてを Decoder RNN に渡すことを考えます。
This is a pen → [Encoder] → 「Encoder RNN の隠れ層の状態(固定長ベクトル)」を時系列順にすべて → [Decoder] → これは 1本の ペン です
Decoder RNN では、自身の RNN のある時点において、Encoder から渡された隠れ層の状態のうち、どの時点の状態を重視すべきかというパラメータを学習します。この機構を Attention とよびます。
事前学習
勾配消失問題を回避するために、当初は事前学習が用いられていました。活性化関数を工夫することで勾配消失問題を回避できることが分かったため、最新の手法では使われません。
2006年に、トロント大学のジェフリー・ヒントンによって提唱されました。
オートエンコーダ (自己符号化器)
入力したデータと同じ出力が得られるように、一つの隠れ層を学習します。
隠れ層の次元は入力層および出力層 (可視層とよびます) よりも小さくなるようにします。
隠れ層には、入力データの情報が圧縮されて要約されることになります。
- 「入力層 → 隠れ層」の処理をエンコード。
- 「隠れ層 → 出力層」の処理をデコードとよびます。
積層オートエンコーダ
オートエンコーダの隠れ層を学習が完了したら、更に層を追加してオートエンコーダを構成します。
積み重ねることで、次元数を小さくしていき、全体として積層オートエンコーダを構成します。
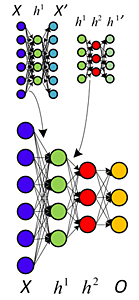
順番に重みを学習するため、勾配消失の問題が発生しづらくなります。
積層オートエンコーダの学習は「教師なし学習」です。
ファインチューニング
積層オートエンコーダに
- 二値分類の場合はシグモイド関数、を用いたロジスティック回帰層
- 多値分類の場合はソフトマックス関数、を用いたロジスティック回帰層
- 分類問題ではなく回帰問題の場合は、線形回帰層
を足します。
積層オートエンコーダで学習済みのパラメータ、および新規に追加した層のパラメータを「教師あり学習」します。
これをファインチューニングとよびます。
出力層においては勾配消失問題が発生せず、入力層に近づくにつれて発生していた勾配消失問題は、積層オートエンコーダのパラメータが事前学習済みのため発生しづらくなっています。
深層信念ネットワーク
ニューラルネットワークと類似したネットワークに「深層信念ネットワーク」があります。
深層信念ネットワークにおいても事前学習が行われており、オートエンコーダに相当する箇所を、制限付きボルツマンマシン (RBM; Restricted Boltzmann Machine) とよびます。
バーニーおじさんのルール
- ディープラーニングを行なうために必要となるデータ数の経験則です。
- 「モデルのパラメータ数の 10 倍のデータ数が必要」という内容です。
- 層が深いネットワークでは、現実的ではないデータ数が必要ということになってしまいます。
- データ数が少なくても済むようなテクニックを適用することになります。